Reviers, 18 novembre 2024
Maintenant que nous sommes rassurés suite à l’installation de solutions de sauvegarde, il est temps de s’occuper de la supervision de notre instance. Il existe différents types d’outils, certains en ligne de commande, certains graphiques (généralement une application web), certains font de la rétro-analyse alors que d’autres font de la supervision en direct. Encore une fois avec PostgreSQL, les outils sont nombreux et la difficulté vient principalement du choix offert.

Nous allons nous pencher sur quatre outils, les trois premiers en ligne de
commandes, le dernier étant une application web : pg_activity, pgbadger,
pgcluu et temboard. Puis, nous ferons un tour rapide des autres outils
graphiques, parfois des solutions complètes, parfois des greffons à des
solutions plus génériques.
pg_activity
pg_activity est un outil qui ressemble
fort à top, mais qui, à la place des processus, affiche les connexions au
serveur PostgreSQL, avec un bon nombre d’informations sur chaque connexion.
L’installation est assez simple :
dnf install -y pg_activity python3-psycopg3 python3-typing-extensions
Le paquet python3-psycopg3 permet d’installer le pilote PostgreSQL pour
Python, dont le nom est psycopg.
Une fois l’outil installé, il est possible de le lancer. Pour trouver certaines
informations, pg_activity se connecte à PostgreSQL. Il est donc nécessaire que
la connexion au serveur PostgreSQL soit possible à partir de l’utilisateur Unix
qui lance l’outil. Le plus simple est évidemment d’utiliser l’utilisateur Unix
PostgreSQL mais n’importe quel autre utilisateur Unix peut faire l’affaire avec
une bonne configuration des rôles et des fichiers pg_hba.conf et
pg_ident.conf.
La copie d’écran en figure 1 montre cet outil en action.
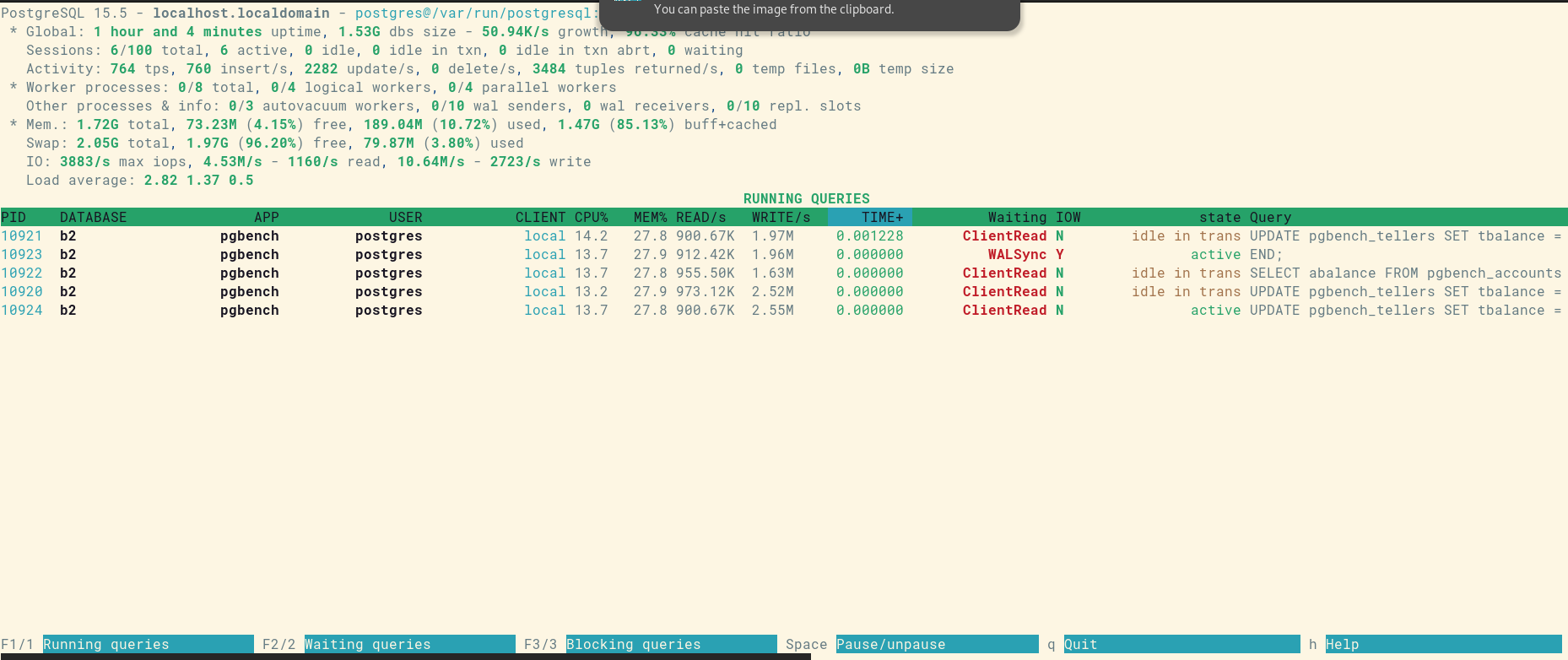
Cet outil affiche donc dans un tableau toutes les connexions en cours sur l’instance PostgreSQL où il est connecté.
L’entête affiche en première ligne la version de PostgreSQL, le nom de l’hôte,
la chaîne de connexion. Il y a ensuite une partie Global avec la durée
d’exécution du serveur, la taille des bases, l’activité des sessions et celles
des transactions. Une partie sur les processus détaille les processus workers
(autovacuum, parallélisation, réplication logique), ainsi que d’autres processus
(notamment la réplication physique). Enfin, une dernière partie donne des
informations sur l’utilisation des ressources matérielles (mémoire, swap,
disques, CPU).
En dessous de cet entête se trouve un tableau des connexions. Pour chaque connexion, il y a le PID du processus serveur, le nom de la base, le nom de l’application (si cette dernière indique son nom), le nom de l’utilisateur connecté, l’adresse IP du client ou local dans le cas d’une connexion socket, le pourcentage d’utilisation du CPU et de la mémoire, la volumétrie lue et écrite par seconde, la durée d’exécution, l’attente ou non d’un événement, l’attente ou non d’une opération disque, l’état du processus et enfin la requête.
Le bandeau du bas indique les actions possibles :
F1permet de lister les processus exécutant des requêtes ;F2permet de lister uniquement les processus dont les requêtes sont en attente d’un verrou ;F3permet de lister uniquement les processus bloquant les requêtes d’autres processus ;- la touche
Espaceest une bascule pour mettre en pause le rafraichissement ou supprimer la pause ; qpermet de quitter ;hpermet d’obtenir l’aide.
En se déplaçant avec les flèches haute et basse, le rafraichissement est en pause, et il est possible de cibler spécifiquement un processus. Dans ce cas, le bandeau change pour donner les actions possibles sur ce processus :
Cpour annuler la requête en cours ;Kpour tuer la connexion ;- la touche
Espaceest une bascule pour sélectionner ou désélectionner des processus, ce qui permet ensuite de réaliser les opérationsCetKsur les processus sélectionnés ; qpour quitter ;- n’importe quel autre touche pour revenir à l’écran précédent.
Il est donc possible avec cet outil d’annuler une requête qui prend trop de ressources du serveur, ou d’annuler une connexion si cette dernière bloque la requête d’une autre connexion. Une confirmation est demandée dans les deux cas, comme le montre la figure 2.

pgBadger
pgBadger est un outil d’analyse des fichiers de
trace de PostgreSQL. De ce fait, il ne se connecte pas au serveur PostgreSQL, il
a juste besoin des fichiers de trace à analyser. Parfois, il est nécessaire de
lui expliquer comment il peut retrouver certaines informations, ce qui revient
généralement à lui donner la configuration du paramètre log_line_prefix de
PostgreSQL.
L’installation est très simple là aussi :
dnf install -y pgbadger
Des modules Perl supplémentaires sont potentiellement installés pour que
pgbadger puisse fonctionner correctement.
L’analyse n’est pas en direct, elle se fait après coup. Donc généralement, nous
récupérons un fichier de trace (ou plusieurs) et nous le fournissons à la
commande pgbadger. Cela se fait ainsi :
$ pgbadger postgresql-Mon.log
[========================>] Parsed 107386 bytes of 107386 (100.00%), queries: 0, events: 26
LOG: Ok, generating html report...
Ici, pgBadger a trouvé 26 événements, mais aucune requête. Ceci est dû au fait
que notre configuration actuelle ne demande pas la trace des requêtes exécutées.
L’un des gros intérêts de pgBadger est de pouvoir calculer des statistiques sur
les requêtes et de pouvoir nous afficher un tableau contenant le top 20 des
requêtes les plus consommatrices. Dans le cas d’un audit, je passe le paramètre
log_min_duration_statement à la valeur la plus basse possible, 0 étant parfait
mais pas toujours faisable. En effet, plus PostgreSQL trace de requêtes, plus
cela peut ralentir la production. Il convient donc d’être prudent. Nous allons
le passer à 0 temporairement ici :
$ psql -qc "ALTER SYSTEM SET log_min_duration_statement TO 0"
$ psql -Atc "SELECT pg_reload_conf()"
t
À partir de maintenant, toute requête exécutée est tracée avec sa durée
d’exécution. Lançons un peu d’activité avec pgbench :
pgbench -c 5 -T 1800 b2
Et récupérons un rapport pgBadger. Pour faciliter la lecture, nous allons demander un rapport au format texte et uniquement sur les requêtes :
pgbadger -x txt --normalized-only postgresql-Mon.log
Voici le début du fichier texte (dont le nom est par défaut out.txt pour le
format texte) :
pgBadger :: Normalized query report
- Global information ---------------------------------------------------
Generated on Mon Dec 18 11:41:46 2023
Log file: postgresql-Mon.log
Parsed 815,790 log entries in 19s
Log start from 2023-12-18 09:19:49 to 2023-12-18 11:41:00
Count Query
----------------------------------------------------------------------
43411 begin;
43411 update pgbench_accounts set abalance = abalance + ? where aid = ?;
43411 update pgbench_branches set bbalance = bbalance + ? where bid = ?;
43411 end;
43411 update pgbench_tellers set tbalance = tbalance + ? where tid = ?;
Nous voyons ici que les requêtes les plus fréquentes ont été des UPDATE sur
les tables pgbench_*, ainsi que des BEGIN et END (un alias de COMMIT).
Le fait qu’elles sont exécutées exactement le même nombre de fois est dû à
pgbench qui exécute exactement le même scénario (en dehors des constantes) un
grand nombre de fois. Les points d’interrogation dans les requêtes sont une
fonctionnalité de pgBadger. Quand ce dernier trouve une requête, il va supprimer
toutes les constantes, quelque soit leur type, pour les remplacer par un point
d’interrogation. Cela lui permet de savoir si un type de requête particulier est
exécuté plusieurs fois ou non, et quand.
Le rapport au format texte est assez basique. Le rapport au format HTML est bien plus intéressant, et c’est d’ailleurs le format par défaut. Il contient beaucoup plus d’informations, y compris des graphes interactifs, qui permettent de mieux appréhender l’activité du serveur. L’outil pgBadger est capable de fournir des rapports sur à peu près toutes les activités tracées du serveur : les connexions, les sessions, l’autovacuum, les verrous, les checkpoints, les requêtes, les messages d’erreur, etc. Mais ceci n’est possible que si ces activités sont tracées. C’est pourquoi, lors du deuxième article de cette série, nous avons activé la trace d’un grand nombre d’activités.
Dans les fonctionnalités très intéressantes de pgBadger, il existe un mode
incrémental permettrant de générer des rapports pour chaque journée. Il faut
pour cela avoir un répertoire de stockage et indiquer ce dernier à la commande
pgbadger :
$ install -d -o postgres -g postgres -m 700 /srv/monitoring/pgbadger
$ pgbadger --incremental --outdir /srv/monitoring/pgbadger postgresql-Mon.log
[========================>] Parsed 53024343 bytes of 53024343 (100.00%), queries: 303890, events: 37
LOG: Ok, generating HTML daily report into /srv/data/log/toto/2023/12/18/...
LOG: Ok, generating HTML weekly report into /srv/data/log/toto/2023/week-52/...
LOG: Ok, generating global index to access incremental reports...
Et voici la hiérarchie de fichiers et répertoires générés :
$ tree /srv/monitoring/pgbadger
/srv/monitoring/pgbadger
├── 2023
│ ├── 12
│ │ └── 18
│ │ ├── 2023-12-18-15921.bin
│ │ └── index.html
│ └── week-52
│ └── index.html
├── index.html
└── LAST_PARSED
4 directories, 5 files
Aller plus loin dans les options de la commande pgbadger ainsi que dans la
description d’un rapport pgBadger irait au délà de ce simple article. Pour les
options, le meilleur conseil est de lire la documentation complète sur cet
outil. Vous pouvez aussi lire
l’article sur pgBadger du Hors-Série 54 de Linux
Pratique.
Avant d’aller plus, revenons à une valeur plus saine du paramètre
log_min_duration_statement après notre pseudo-audit :
$ psql -qc "ALTER SYSTEM SET log_min_duration_statement TO 1000"
$ psql -Atc "SELECT pg_reload_conf()"
t
pgCluu
pgCluu est un outil du même auteur que pgBadger.
pgCluu récupère les informations des catalogues statistiques de PostgreSQL et
les enregistre dans des fichiers CSV pendant tout le temps de l’exécution de sa
sonde. Une fois qu’elle a recueilli suffisamment d’informations, il est possible
de procéder à la création d’un rapport HTML. pgCluu est donc composé de deux
outils : pgcluu_collectd pour la récupération des métriques et pgcluu pour
la génération du rapport.
L’installation est encore une fois très simple :
dnf install -y pgcluu
Le paquet sysstat est une dépendance du paquet pgcluu. Il sera installé sur
le système si ce n’est pas déjà le cas. Ce paquet est utilisé pour récupérer des
métriques sur l’utilisation des ressources matérielles du serveur (processeurs,
mémoire, disque).
Un service et un timer systemd sont installés. Il est plus simple de passer
par eux pour mettre en place la sonde.
Commençons par éditer le service de la sonde :
systemctl edit pgcluu_collectd
Dans l’éditeur qui vient de s’ouvrir, nous allons ajouter ceci :
[Service]
Environment=STATDIR=/srv/monitoring/pgcluu/csv
Le répertoire indiqué pour le stockage des fichiers CSV doit exister avant de lancer la sonde. Nous allons donc le créer :
install -d -o postgres -g postgres -m 700 /srv/monitoring/pgcluu/csv
Maintenant, éditons le service pgcluu :
systemctl edit pgcluu
Et ajoutons ceci dans le fichier ouvert :
[Service]
Environment=STATDIR=/srv/monitoring/pgcluu/csv
Environment=REPORTDIR=/srv/monitoring/pgcluu/report
Nous pouvons aussi l’activer :
systemctl enable pgcluu
Il est possible de créer le répertoire pour le stockage des rapports mais ce
n’est pas une obligation. Le service pgcluu s’en charge si ce n’est pas déjà
fait.
Enfin, il faut activer le timer :
systemctl enable pgcluu.timer
Et démarrer les services :
systemctl start pgcluu_collectd
systemctl start pgcluu.timer
À partir de là, la sonde récupérera les métriques du système avec sysstat et
de PostgreSQL dans les catalogues statistiques de ce dernier toutes les minutes.
Cet intervalle est configurable sur la ligne de commande de l’outil (et de ce
fait dans la configuration du service pgcluu_collectd).
Le rapport est généré automatiquement toutes les cinq minutes par le timer
pgcluu. C’est ce dernier qu’il faut modifier pour changer la fréquence de
création du rapport via les paramètres OnBootSec et OnUnitActiveSec.
La configuration réalisée ici stocke le résultat dans le répertoire
/srv/monitoring/pgcluu/report, mais nous pourrions très bien l’envoyer
directement dans un répertoire servi par un serveur HTTP comme Nginx.
pgCluu n’ayant pas fait l’objet d’un article, nous allons discuter très rapidement des points à connaître sur cet outil. La figure 3 montre la page d’accueil d’un rapport pgCluu.
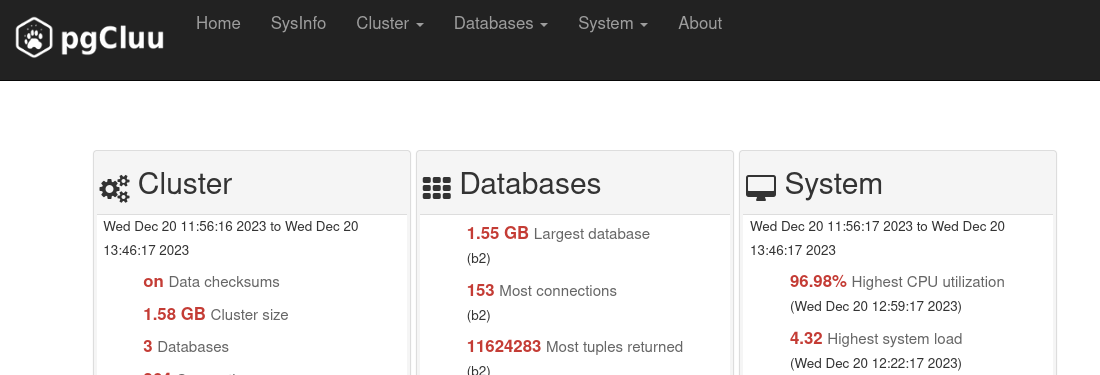
Comme pour les rapports pgBadger, un bandeau en tête de page permet d’accéder
aux différents rapports possibles. Généralement, le premier à regarder est celui
sur le système (System). Il permet d’avoir une idée générale de l’utilisation
des ressources (CPU, mémoire, disques, ainsi que réseau, même si je n’ai jamais
eu l’occasion d’utiliser ce dernier). Il est donc possible, avant d’avoir
regardé les métriques spécifiques à PostgreSQL, de connaître la consommation des
CPU et des disques.
La partie Cluster est l’autre partie essentielle pour moi. Plusieurs rapports
sont intéressants :
Connections/Connections by type, pour trouver le décompte des connexions par type (actives, inactives, inactives en transaction, en attente d’un verrou) ;Cache utilization, pour vérifier que le cache disque de PostgreSQL fait bien son office ;Background writer/Bgwriter buffers written, pour savoir qui écrit sur disque les blocs des fichiers de données modifiés ;Temporary files/Temporary files size, pour voir la quantité de fichiers temporaires écrits (le rapport pgBadger est plus intéressant sur ce point car il indique aussi les requêtes qui sont responsables de ces écritures) ;WAL checkpoint/WAL files, pour avoir une idée des écritures réalisées dans les journaux de transactions ;WAL checkpoint/Checkpoints counter, pour savoir si les checkpoints sont déclenchés suite au dépassement du délai (paramètrecheckpoint_timeout) ou au dépassement de la volumétrie écrite dans les journaux (paramètremax_wal_size) ;Queries Read Write / Write ratio, pour connaître l’activité en écriture de l’instance (plutôt desINSERT? Ou desUPDATE? Etc) ;Transaction throughput, pour connaître le nombre de transactions par seconde (attention, il s’agit bien ici du nombre de transactions, pas du nombre de requêtes, ça n’est pas du tout équivalent).
Il existe plein d’autres informations disponibles mais elles sont généralement moins intéressantes (en tout cas pour moi, lors d’un audit).
La partie Databases permet d’avoir une partie de ces informations séparées par
base, mais aussi d’autres informations très intéressantes comme les index
inutilisés, les index manquants, etc.
La figure 4 montre le graphe sur les connexions par type.
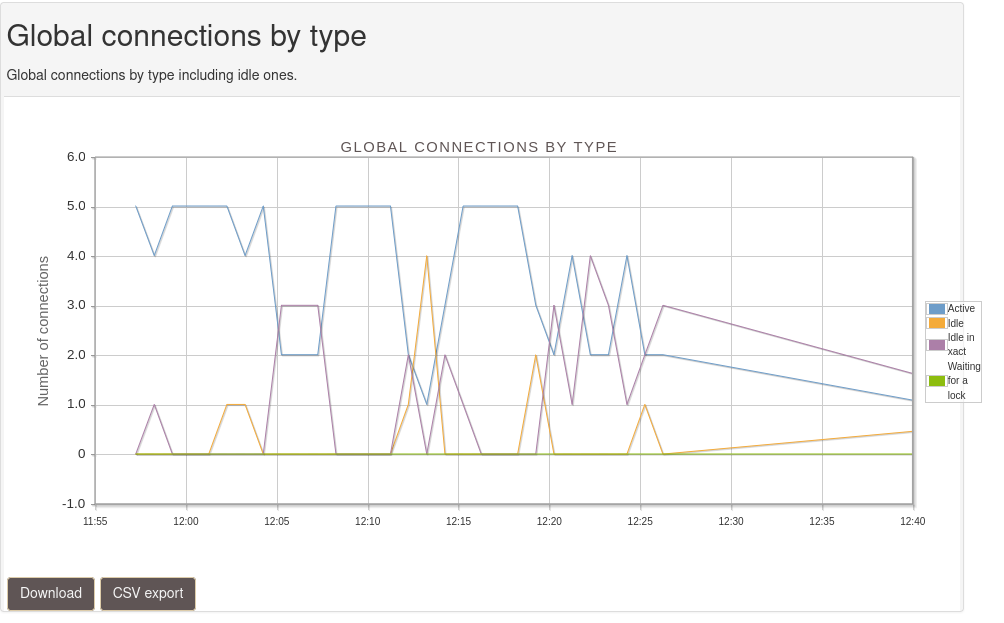
Il convient de faire attention à la rétention des métriques. Par défaut, aucune
purge n’est effectuée. Il est cependant possible de configurer une rétention
maximale des métriques dans pgcluu. Pour cela, voir l’option --retention.
temboard
Temboard est un outil libre dont le but est
la gestion d’un parc d’instances PostgreSQL. Il comprend deux composants : l’UI
(temboard) et l’agent (temboard-agent). L’agent sera à déposer sur chaque
instance à gérer.
L’installation est un peu plus complexe que pour les autres outils encore vus, mais il n’y a rien non plus de sorcier.
Commençons par ajouter le dépôt adéquat :
dnf install -y https://yum.dalibo.org/labs/dalibo-labs-4-1.noarch.rpm
Nous pouvons maintenant installer l’application web :
dnf install -y temboard
Pour information, la version installée sur ma VM était la 8.2.1.
Un script permet sa configuration, nous allons l’exécuter (en tant que root) :
# /usr/share/temboard/auto_configure.sh
Creating system user temBoard.
Configuring temboard in /etc/temboard.
Generating self-signed certificate.
Creating Postgres user, database and schema.
Success. You can now start temboard using:
systemctl enable --now temboard
Remember to replace default admin user!!!
Ce script crée un utilisateur système spécifique pour temBoard, configure l’interface, génère un certificat auto-signé et enfin, crée une base de données (qu’il peuple) et un rôle.
Nous pouvons maintenant lancer le service temboard :
systemctl enable --now temboard
À ce moment-là, il faut utiliser un navigateur web pour accéder à l’application web en utilisant l’URL https://serveur:8888. Pour la connexion, l’utilisateur par défaut est admin, le mot de passe est aussi admin, et il est très fortement conseillé de changer le mot de passe.
Attention, sur ma VM (et donc tout système RedHat et compatible), il est nécessaire de configurer le pare-feu pour accéder à la page web. Voici comment faire :
firewall-cmd --add-port 8888/tcp --permanent
firewall-cmd --reload
Pour que temboard nous affiche des informations, il va falloir installer
l’agent. C’est parti :
dnf install -y temboard-agent
Là aussi, un script de configuration automatique est disponible :
# TEMBOARD_HOSTNAME=localhost.localdomain /usr/share/temboard-agent/auto_configure.sh https://localhost.localdomain:8888
Using hostname localhost.localdomain.
Configuring for PostgreSQL user postgres.
Configuring for cluster on port 5432.
Configuring for cluster at /srv/data.
Using /usr/pgsql-15/bin/pg_ctl.
Cluster name is 15/pg5432.
Configuring temboard-agent in /etc/temboard-agent/15/pg5432/temboard-agent.conf .
Configuring temboard-agent to run on port 2345.
Configuring systemd unit temboard-agent@15-pg5432.service.
Success. You now need to fetch UI signing key using:
sudo -u postgres temboard-agent -c /etc/temboard-agent/15/pg5432/temboard-agent.conf fetch-key
Then start agent service using:
systemctl enable --now temboard-agent@15-pg5432.service
See documentation for detailed instructions.
Il ne reste plus qu’à récupérer la clé :
temboard-agent -c /etc/temboard-agent/15/pg5432/temboard-agent.conf fetch-key
et démarrer le service de l’agent :
systemctl enable --now temboard-agent@15-pg5432.service
Le reste se fait sur l’interface web. Il faut aller dans la configuration (lien Settings) pour ajouter l’instance. Une fois ceci fait, nous arrivons sur cet écran :
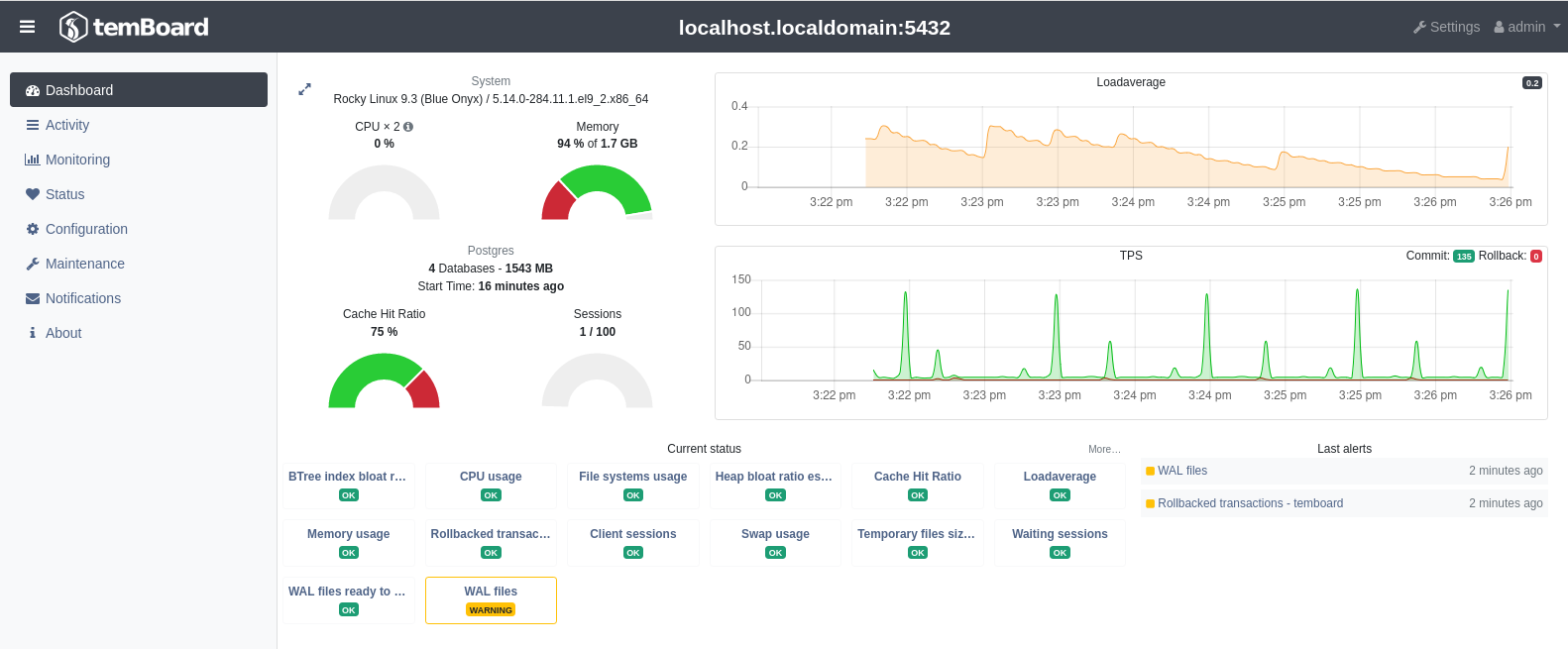
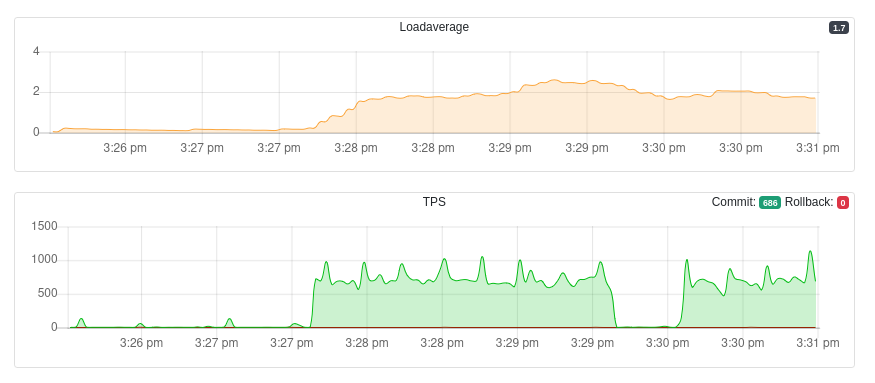
Nous sommes ici sur le tableau de bord d’une instance. Plusieurs graphes sont
affichés, ainsi que le statut de plusieurs sondes. Voici les mêmes graphes avec
de l’activité générée avec pgbench :
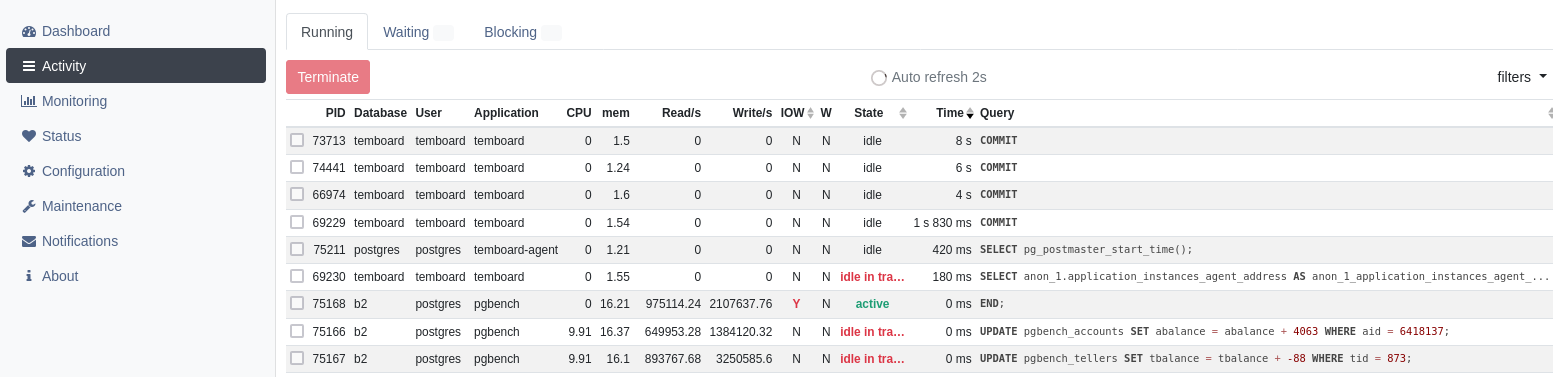
Le menu à gauche permet de réaliser différentes actions. La partie Activity
devrait vous rappeler l’interface de l’outil pg_activity, mais cette fois-ci
en version web. La figure 7 montre cette partie. La partie Monitoring permet
de sélectionner et d’afficher les graphes importants. La partie Status
concerne les statuts des sondes. En cliquant sur une sonde, nous aboutissons à
son graphe. La partie Configuration permet de configurer l’instance à
distance. La partie Maintenance permet de visualiser le niveau de
fragmentation des bases, tables et index, suivant le niveau de profondeur
demandé. Elle permet aussi de lancer des actions de maintenance comme un
VACUUM ou un REINDEX par exemple.
Outils plus avancés
Il existe des outils plus avancés ou plus graphiques que ceux présentés ci-dessus.
Il est tout à fait possible d’utiliser des outils comme Nagios (ou un de ses forks) ou Zabbix avec une sonde comme check_pgactivity.
Il est possible d’utiliser des outils plus modernes comme Prometheus, à qui il faut adjoindre un exporteur pour PostgreSQL. Le plus couramment utilisé s’appelle postgres_exporter.
PoWA est un outil très différent, conçu
uniquement pour PostgreSQL, et dont le
but est de voir les requêtes exécutées et un certain nombre de métriques sur ces
requêtes. Il se repose notamment sur l’extension pg_stat_statements (que nous
avons mis en place dans l’article sur l’installation du serveur). Cet outil est
assez unique en son genre, et est particulièrement utile.
Petite conclusion
À vous de tester ces différents outils et de sélectionner ceux qui vous intéressent le plus.
N’oubliez pas de mettre à jour régulièrement ces outils. Ils sont activement développés et toute amélioration pourrait vous faire découvrir des informations intéressantes sur votre instance. De plus, en cas de mise à jour majeure de PostgreSQL, ils seront à mettre à jour pour qu’ils puissent analyser les nouvelles traces et métriques fournies par la nouvelle version de PostgreSQL.
Depuis quelques années, Guillaume Lelarge publie des articles dans le magazine « Linux Pratique » édité par les Éditions Diamond. Avec leur accord, il reprend ici une série destinée à guider l’installation, la maintenance et l’utilisation de PostgreSQL.