Lyon, le 26 mars 2024
Voici le troisième article de notre série pour essayer de comprendre davantage
le moteur PostgreSQL. Après avoir décortiqué le mécanisme de TOAST (voir notre
précédent article), attardons-nous sur quelque chose de plus pointu : l’accès aux buffers.

Nous allons voir comment PostgreSQL fait en sorte que l’accès aux buffers ne soit pas trop chaotique en se focalisant sur les stratégies d’accès.

Quésaco ?
Une stratégie d’accès est un moyen mis en œuvre pour contrôler l’utilisation des buffers de la mémoire partagée (shared buffers) de PostgreSQL. Le principe est de limiter le nombre de blocs du cache utilisables par une opération afin qu’elle n’impacte pas trop les autres opérations en train de s’exécuter. Par opération, il s’agit de tout processus qui nécessite d’accéder, en lecture ou écriture, au cache de PostgreSQL.
Prenons un exemple assez simple d’un cache PostgreSQL de 128 ko (taille
minimale acceptée par le paramètre shared_buffers). Représentons le de la
manière suivante :
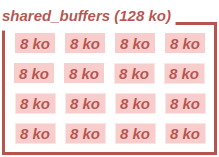
et prenons l’exemple d’un client backend exécutant une opération devant accéder à quelques buffers. D’autres processus (d’autres clients, notamment) accèdent également aux buffers restants.
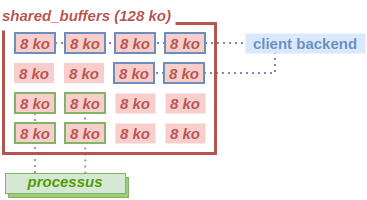
Supposons que ce client backend lise beaucoup de blocs, qui se retrouvent dans le cache mémoire. Si aucune limite n’est appliquée, cela impacterait le cache disponible pour les autres processus. Nous comprenons facilement que les autres processus seraient fortement impactés (temps d’exécution plus longs, demandes de lectures sur disques plus nombreuses…).
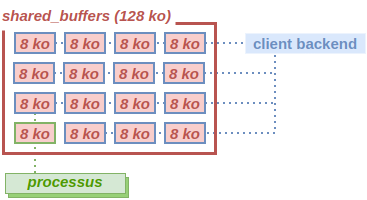
Pour parer à cela, PostgreSQL peut appliquer une « stratégie
d’accès ». Elle définit un nombre limité de blocs en
cache destinés à être réutilisés cycliquement (on parle aussi de ring buffer).
Jusqu’à la version 15, PostgreSQL limite l’accès à 256 ko du cache au client backend. Dans notre exemple, on considère la valeur de 64ko, soit la moitié de shared_buffers.
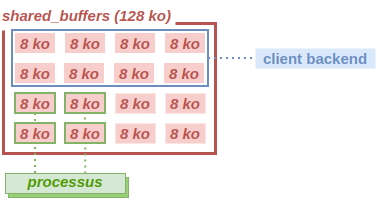
Les autres processus ne verront donc pas leurs ressources leur être retirées.
Si le client backend a besoin de charger de nouvelles données alors qu’il utilise déjà les 64 ko alloués, il devra d’abord recycler un bloc. Ce recyclage pourra mener à une écriture sur disque des données (flush).
PostgreSQL n’applique une stratégie d’accès aux buffers que pour certaines
opérations bien définies, comme des opérations de VACUUM, de
COPY, ou de Seq Scan sur des tables volumineuses. Les stratégies ne sont pas
tout à fait les mêmes selon l’opération, mais le principe reste le même :
éviter qu’une opération utilisant de nombreux blocs n’en remplisse le cache.
Paramètre vacuum_buffer_usage_limit
La version 16 embarque une nouveauté très intéressante qui permet de configurer
la stratégie d’accès aux buffers pour les opérations de VACUUM et
d’ANALYZE : le paramètre vacuum_buffer_usage_limit. Vous pouvez retrouver le
commit associé à cette nouveauté
ici.
Par défaut à 256 ko, cette valeur peut être configurée jusqu’à 16 Go. Il est
toutefois impossible de le configurer à plus de 1/8ᵉ du paramètre
shared_buffers. Si c’est le cas, PostgreSQL le reconfigure
silencieusement pour respecter cette limite. Enfin, il est possible de le
positionner à 0. Dans ce cas là, aucune limite n’existe et l’opération pourra
utiliser autant de buffers du cache PostgreSQL qu’elle le souhaite.
Ouvrons une rapide parenthèse concernant le risque de wraparound des identifiants de
transactions. Depuis la version 14 de PostgreSQL, il existe un mécanisme de
protection (failsafe) qui permet d’exécuter un VACUUM si l’identifiant le plus ancien
d’une table est trop loin dans le passé (le commit associé à cette nouveauté
peut être retrouvé
ici).
En version 16, lorsque ce mécanisme se déclenche, la stratégie d’accès est
désactivée et autorise donc l’opération à accéder à tous les buffers
disponibles pour se faire au plus vite.
When the failsafe is triggered, any cost-based delay that is in effect will no longer be applied, further non-essential maintenance tasks (such as index vacuuming) are bypassed, and any Buffer Access Strategy in use will be disabled resulting in VACUUM being free to make use of all of shared buffers.
Benchmark
L’idée de notre test est de voir l’influence de ce paramètre (qu’elle soit
positive ou négative) sur une opération de VACUUM. Ce paramètre est ajustable
avec l’option BUFFER_USAGE_LIMIT de VACUUM.
L’outil pgbench a été utilisé pour créer une base de données de
test et avoir une situation de départ identique pour chaque test.
30 millions de lignes sont insérées et un tiers sont mises à jour pour que
l’opération de VACUUM ait une bonne raison de travailler.
Le VACUUM a été lancé avec l’option BUFFER_USAGE_LIMIT positionnée à 0, 256,
1024 et enfin 4096. Pour chaque test, des statistiques sur les I/O et les
journaux de transaction (WAL) ont été rélevées.
Voici les résultats obtenus :
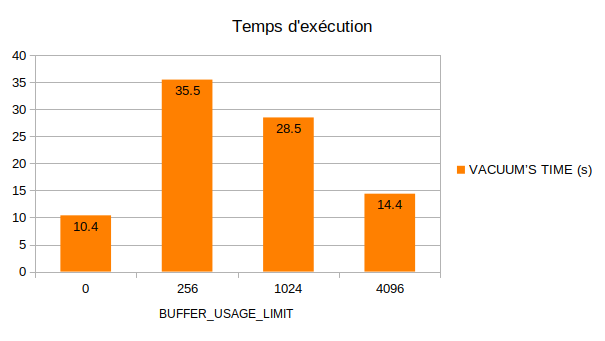
Première conclusion évidente : plus la mémoire attribuée à VACUUM est grande,
plus le temps d’exécution est rapide.
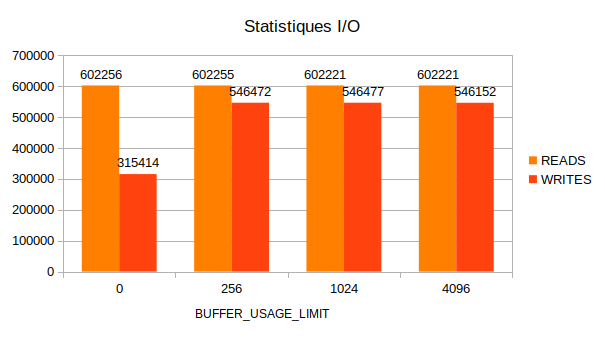
Le compteur WRITES (extrait de la vue pg_stat_io) montre que lorsque l’accès
aux buffers n’est pas limité, il est moins nécessaire de demander au système
des écritures disques (flush). Pour les autres cas, les nombres de demandes
sont identiques.
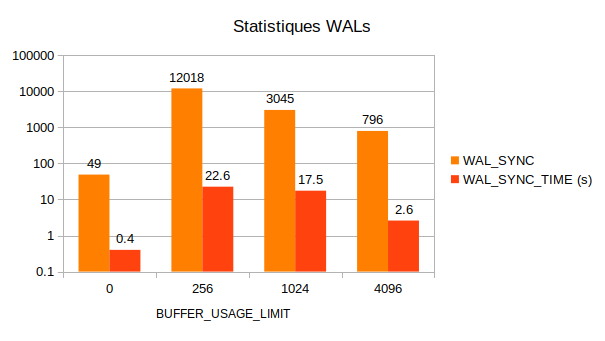
wal_sync (de la vue pg_stat_wal) indique le nombre de fois où les fichiers de
transactions ont été synchronisés sur disque. Là encore, une nette différence
est présente lorsqu’aucune limite n’est appliquée. 49 opérations fsync ont été
nécessaires lorsque BUFFER_USAGE_LIMIT est à 0 contre 12018 avec la
configuration par défaut. Comme souvent avec PostgreSQL, il est possible d’en
savoir un peu plus grâce aux commentaires du code source. En l’occurrence, le
fichier postgresql/src/backend/storage/buffer/README apporte une explication
sur le résultat obtenu :
VACUUM uses a ring like sequential scans, however, the size of this ring is controlled by the vacuum_buffer_usage_limit GUC. Dirty pages are not removed from the ring. Instead, WAL is flushed if needed to allow reuse of the _buffers.
Les journaux de transaction associés aux écritures d’un VACUUM sont synchronisés sur disque lorsqu’il faut réutiliser les buffers correspondants en mémoire partagée. Plus grand est le ring buffer, moins fréquentes sont ces synchronisations.
Conclusion
Ces résultats montrent que l’exécution de VACUUM peut être améliorée en
modifiant le paramètre contrôlant l’accès aux shared_buffers. Pour autant, il
ne faut pas oublier qu’en ne limitant pas l’accès aux shared_buffers, les
autres requêtes et traitements seront impactées et leurs performances dégradées.
Il est tout à fait imaginable de positionner ce paramètre à 0 dans le cas d’une
plage de maintenance où il serait possible d’utiliser le maximum de mémoire
partagée pour des opérations de VACUUM. Aussi, après une restauration d’une
grande quantité de données, lancer un ANALYZE est une bonne pratique. Ce
traitement pourrait être accéléré en modifiant BUFFER_USAGE_LIMIT. Voilà une
idée de benchmark que vous pouvez faire.
Et voilà, c’est la fin de cet article des mains dans le cambouis. Nous
venons d’appréhender une nouvelle partie du moteur PostgreSQL.
Les stratégies d’accès sont essentielles au bon fonctionnement de
l’instance. En profitant d’une nouveauté apportée par la version 16, nous avons
vu qu’il est possible d’améliorer le traitement de VACUUM.
Des questions, des commentaires ? Écrivez-nous !
- PostgreSQL (480) ,
- Dalibo (201) ,
- 2024 (6) ,
- mainsdanslecambouis (5) ,
- buffers (1) ,
- planetpgfr (53)