Lyon, le 27 février 2024
Nouvel article dans notre série Les mains dans le cambouis !
Après avoir évoqué les checkpoints lors du premier article (si vous ne l’avez
pas lu, vous pouvez le retrouver
ici), nous vous
proposons aujourd’hui de mettre les mains dans le cambouis du
mécanisme de TOAST.


Quésaco ?
TOAST est le raccourci de The Oversized-Attribute Storage Technique.
Essayons, rien qu’à la lecture de ces mots, de comprendre de quoi il pourrait
s’agir :
- Oversized-Attribute : il est question d’un attribut. Sa taille dépasserait un certain seuil puisque qu’il est qualifié de Oversized ;
- Storage : on comprend que cela va traiter du stockage des données, donc très probablement sur disque ;
- Technique : laisse penser qu’un mécanisme a été trouvé pour arriver à stocker ces données qui seraient trop volumineuses .
Nous avons vu dans le précédent article que PostgreSQL travaille avec des blocs
mémoire de 8 ko pour les shared_buffers. C’est également le cas avec les blocs
de données. Vérifions cette dernière affirmation avec la création d’une table et
regardons, après une insertion, la taille du fichier sur le disque.
postgres=# create table t1 (i int);
Le fichier associé dans l’arborescence de la base est le fichier 17253. À sa
création, sa taille est nulle, mais après l’insertion d’un entier, 8 ko
sont utilisés.
$ ls -alh 17253
-rw------- 1 pierrick pierrick 8,0K janv. 12 14:39 17253
En plus de travailler avec des blocs de 8 ko, PostgreSQL n’autorise pas à ce qu’une ligne puisse être sur plusieurs blocs en même temps. Peu d’applications pourraient fonctionner avec une telle limite… Comment faire, donc, pour stocker des lignes pour lesquelles des éléments de plusieurs kilo-octets doivent être stockés ?
Il existerait bien un moyen pour arriver à cela : par exemple il suffit de supprimer les octets en trop… mais bon, c’est sûrement un peu trop radical 😅. Blague à part, dans PostgreSQL deux méthodes permettent de réduire la taille des données :
- la compression ;
- le découpage en tranches plus petites (tranches - toast, vous avez le lien ? 🍞).
Le choix de la méthode de réduction se fait grâce à la politique de stockage utilisée.
Politiques de stockage
Chaque type de donnée (integer, varchar, text…) possède une politique
de stockage. Pour certains types, elle est immuable (type de données à taille fixe),
pour d’autres, il est possible de la modifier. Selon la politique de stockage,
PostgreSQL va compresser les données et, si la taille n’est toujours pas passée
en dessous du seuil limite, décidera de les découper. La politique de stockage
d’un type peut être trouvée dans la colonne typstorage de la table pg_type.
La voici pour quelques types bien connus :
typname | typstorage
---------+------------
int4 | p
text | x
json | x
varchar | x
numeric | m
Il en existe quatre différentes (p, m, e et x) et chaque politique permet
certaines choses. Voici un tableau résumé de ce qu’elles permettent de faire :
| Lettre | Compression | Découpage |
|---|---|---|
| p : Plain | Non | Non |
| m : Main | Oui | Oui* |
| e : External | Non | Oui |
| x : Extended | Oui | Oui |
Bien que les politiques main et extended permettent la compression et le
découpage, des différences existent. L’une d’entre elles est le fait qu’une
colonne main sera découpée qu’en dernier recours, donc après des colonnes
extended.
Compression
Pour les politiques qui le permettent, la compression peut être déclenchée sur
la donnée à insérer.
Il existe actuellement deux méthodes de compression supportées par PostgreSQL :
pglz (défaut) et lz4 (cette dernière depuis la version 14). L’idée de ce qui va suivre est de voir les
différences notables entre ces deux méthodes de compression.
Prenons l’exemple d’une simple insertion de 8192 caractères dans un champ
text qui a comme politique de stockage plain. Cette politique impose que
toutes les données soient stockées dans la table et sans compression comme
l’indique le tableau du paragraphe précédent.
postgres=# create database demo;
CREATE DATABASE
postgres=# \c demo
You are now connected to database "demo" as user "postgres".
demo=# create table t1 (t text);
CREATE TABLE
demo=# alter table t1 alter column t set storage plain;
ALTER TABLE
demo=# insert into t1 select(repeat('a', 8192));
ERROR: row is too big: size 8224, maximum size 8160
En forçant la politique de stockage à plain, le mécanisme de TOAST n’est pas
mis en oeuvre. Comme PostgreSQL ne travaille qu’avec des blocs de 8 ko,
l’insertion est refusée car elle nécessite trop de place.
Essayons cette fois-ci une insertion de seulement 8000 caractères et regardons la
place prise grâce à la fonction pg_column_size().
demo=# insert into t1 select(repeat('a', 8000));
INSERT 0 1
demo=# select pg_column_size(t) from t1;
pg_column_size
----------------
8004
(1 row)
Quatre octets supplémentaires sont présents. Ils correspondent à quatre octets d’en-tête précisant la taille de la donnée texte.
Passons maintenant à la politique de stockage à main et regardons la
taille de la colonne après une nouvelle insertion. main autorise la
compression des données si PostgreSQL estime que le gain est suffisant par
rapport au coût de cette opération.
demo=# alter table t1 alter column t set storage main;
ALTER TABLE
demo=# insert into t1 select(repeat('a', 8000));
INSERT 0 1
demo=# select pg_column_size(t) from t1;
pg_column_size
----------------
8004
103
(2 rows)
Il ne faut désormais plus que 103 octects pour stocker les données
et ce, grâce à la compression faite automatiquement par PostgreSQL. C’est
nettement plus efficace en termes de place occupée. Par défaut, la méthode
pglz est utilisée. Depuis la version 14, il est possible d’utiliser lz4 pour
la compression. La commande ALTER sur la colonne permet de choisir la
compression souhaitée :
demo=# alter table t1 alter t set compression lz4;
ALTER TABLE
demo=# insert into t1 select(repeat('a', 8000));
INSERT 0 1
demo=# select pg_column_size(t) from t1;
pg_column_size
----------------
8004
103
50
(3 rows)
Pour notre exemple (hyper simpliste, on vous l’accorde) de 8000 caractères a,
lz4 permet de descendre à 50 octets de données, soit un gain de place de plus
de 99%.
Il est possible de connaître à posteriori l’algorithme de compression utilisé
grâce à la fonction pg_column_compression(). Elle renvoie NULL si la
colonne n’a pas été compressée.
demo=# select pg_column_size(t), pg_column_compression(t) from t1;
pg_column_size | pg_column_compression
----------------+-----------------------
8004 |
103 | pglz
50 | lz4
(3 rows)
Ouvrons une parenthèse pour expliquer comment cette fonction sait quel
est l’algorithme de compression utilisé. Elle fait appel à la fonction
toast_get_compression_id()
qui va retourner l’id de la méthode de compression. Cet id est contenu dans les
deux premiers bits de la donnée compressée, stockée dans une variable de type
varlena.
Comme souvent avec PostgreSQL, les commentaires du code permettent de trouver des détails sur ce que l’on cherche. Le commentaire suivant indique que les deux premiers bits de la données sont utilisés pour coder la méthode de compression.
Fermons cette parenthèse pour évoquer enfin le découpage des données et les
deux dernières politiques de stockage, à savoir external et extended.
Découpage
Depuis le début de l’article, on évoque une taille limite qui, si elle est
dépassée, déclenche le découpage de la donnée. Cette taille correspond au
paramètre TOAST_TUPLE_THRESHOLD positionné à 2 ko. La donnée est découpée de
sorte que le nouveau morceau fasse au plus TOAST_MAX_CHUNK_SIZE octets (par
défaut 2000 octets). Le découpage de la donnée se fait jusqu’à ce que la taille
restante soit en dessous de TOAST_TUPLE_TARGET. Ce paramètre peut être modifié
au niveau de la table avec la commande
ALTER TABLE t1 SET (toast_tuple_target = n).
Prenons l’exemple d’une table t1 qui contiendrait des images au format
binaire. Dès lors qu’une table avec une colonne TOAST-able est créée, une
table toast est créée et lui est associée. Pour illustrer uniquement le
découpage des données, la politique d’extension sera positionnée à external.
demo=# create table t2 (t bytea);
CREATE TABLE
demo=# alter table t2 alter column t set storage external ;
ALTER TABLE
demo=# insert into t2 values (pg_read_binary_file('/tmp/image.jpg'));
INSERT 0 1
L’image insérée a une taille de 834 ko. Regardons la taille de la table t2
maintenant que l’image a été insérée :
demo=# select pg_relation_size('t2');
pg_relation_size
------------------
8192
(1 row)
8192 octets… Comment expliquer cette taille ? Et puis 8 ko, c’est étonnant de
retrouver exactement la taille d’un bloc ! Comme dit plus haut, une table toast
existe et est associée à notre table t2. C’est celle-ci qui contient en fait
toutes les données.
-- recherche de la table toast associée
demo=# SELECT c_toast.relname
FROM pg_class c_toast
JOIN pg_class c_heap ON c_heap.reltoastrelid=c_toast.oid
WHERE c_heap.relname='t2';
relname
----------------
pg_toast_17286
(1 row)
demo=# select pg_size_pretty(pg_relation_size('pg_toast.pg_toast_17286'));
pg_size_pretty
----------------
856 kB
(1 row)
Pour vous montrer que les données se trouvent dans la table toast,
on a volontairement utilisé la fonction pg_relation_size() sur la table
toast. Il est plus judicieux d’utiliser la fonction pg_table_size() qui
donne la taille de la table et de sa table toast.
demo=# select pg_table_size('t2');
pg_table_size
---------------
942080
(1 row)
On peut vérifier au passage la taille des lignes de la table toast :
demo=# select count(*), pg_column_size(chunk_data) from pg_toast.pg_toast_17286 group by 2;
count | pg_column_size
-------+----------------
1 | 1728
427 | 2000
(2 rows)
Elles font toutes 2000 octets sauf une, très certainement la dernière, qui elle n’a nécessité que 1728 octets.
Maintenant que le concept du TOAST a été expliqué (politique, compression,
découpage), essayons de voir concrêtement les différences qui existerait entre
les modes de compression.
Benchmarks
Nous avons voulu comparer les performances (en temps et taille sur disque) des deux algorithmes de compression avec l’insertion d’un même jeu de données.
Le premier test consistait à l’ajout de données dans une colonne de type text,
avec par défaut la politique extended. Le premier graphique montre que, pour des
insertions de données déclenchant une compression, lz4 est tout le temps plus
rapide que pglz.
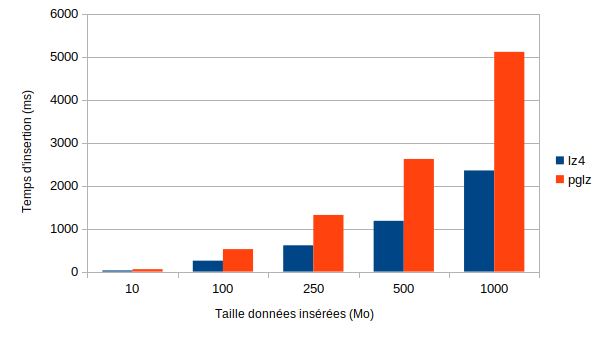
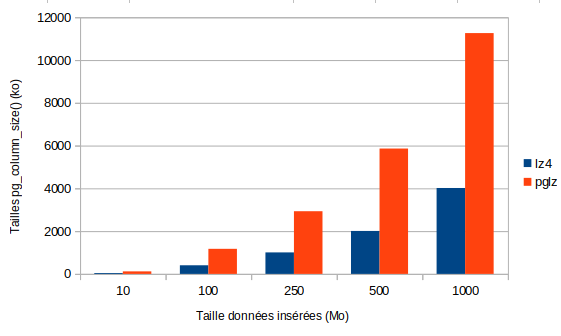
Le graphique suivant nous permet de conclure que, là aussi, lz4 est plus
performant que pglz en termes de volumétrie gagnée.
Conclusion
C’est donc la fin de notre article Les mains dans le cambouis sur
le mécanisme de TOAST, le second de notre série.
Ce mécanisme, bien qu’invisible aux utilisateurs ou aux développeurs, est essentiel au fonctionnement de PostgreSQL. Les développeurs doivent garder en tête que, pour stocker de larges données, il ne leur est pas nécessaire de découper eux-mêmes les éléments. Laissez faire PostgreSQL, il sait très bien faire cela.
La compression joue également un rôle dans le stockage des données comme nous avons pu le voir avec notre benchmark. Testez vous aussi les deux algorithmes de compression pour voir lequel des deux est le plus efficace pour stocker vos données.
Dans quelques semaines, le troisième article sera publié. Au programme, ring buffer : décodage logique ou plongeons dans les journaux de transactions ? Les idées sont là, mais on va garder la surprise pour nous ^^.
Des questions, des commentaires ? Écrivez-nous !
- PostgreSQL (476) ,
- Dalibo (199) ,
- mainsdanslecambouis (5) ,
- TOAST (1) ,
- stockage (4) ,
- planetpgfr (50)