Paris, le 22 septembre 2022
Après le rappel des fondamentaux et des approches possibles, nous abordons aujourd’hui la réplication.
Réplication : de quoi parle-t-on ?
Soyons précis : la réplication n’est pas à proprement parler une sauvegarde, tout comme le miroir d’un disque en RAID 1 n’est pas une sauvegarde. Il s’agit plutôt une protection contre la défaillance, qui permet de répondre à plusieurs objectifs de la sauvegarde : protection contre les pannes matérielles, duplication des données entre différents serveurs avec une faible latence. Elle est inadaptée pour se protéger d’une erreur humaine… qui sera répliquée aussi ! Une sauvegarde par un autre moyen (PITR notamment) est nécessaire.
La réplication est le processus de partage d’informations permettant de garantir la sécurité et la disponibilité des données entre plusieurs serveurs. Chaque SGBD dispose de différentes solutions et introduit sa propre terminologie.
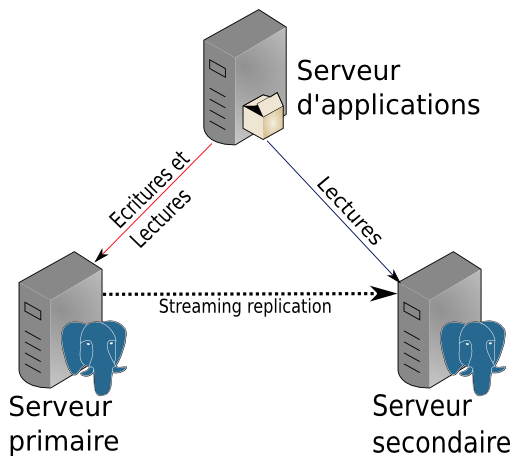
Principe & limites de la réplication physique de PostgreSQL
La réplication physique est une réplication au niveau bloc. Le serveur primaire envoie au secondaire les octets à ajouter/remplacer dans des fichiers. Le processus sur le serveur secondaire qui va traiter ces données n’a aucune information sur les objets logiques (tables, index, vues matérialisées, bases de données). Il n’y a donc pas de granularité possible, c’est forcément l’instance complète qui est répliquée. La réplication physique est souvent mise en place en même temps que le PITR, car les bases techniques sont les mêmes. Selon la défaillance, on opérera une restauration PITR, ou on basculera sur un secondaire.
La réplication physique est par défaut en asynchrone mais il est possible de la configurer en synchrone suivant différents modes : la réplication asynchrone et la réplication synchrone.
La réplication asynchrone
Dans la réplication asynchrone, les écritures sont faites sur le primaire et le client a un retour lui confirmant l’enregistrement de la transaction avant même qu’elle ne soit poussée vers le secondaire. La mise à jour des tables répliquées est différée (asynchrone). Selon la technique, l’infrastructure et la charge, le délai peut être très bref ou s’étaler sur des heures, mais le client ne le voit pas.
- RPO : faible
- RTO : moyenne
Avantages :
- un autre serveur est prêt à prendre la relève
- répartition possible de la charge sur les secondaires (en lecture)
Inconvénients :
- complexité de mise en œuvre (architecture et configuration)
- les écritures sur les serveurs secondaires sont différées
- perte de données possible en cas de crash du primaire
La réplication synchrone
Dans la réplication synchrone, le client envoie sa requête en écriture sur le serveur primaire, le serveur primaire l’écrit sur son disque, envoie les données au serveur secondaire, et attend que ce dernier l’écrive sur son disque. Si tout ce processus s’est bien passé, le client est averti que l’écriture a été réalisée avec succès (concrètement : un ordre COMMIT rend la main). Ce n’est qu’après tout ce traitement que le client peut envoyer une autre requête à exécuter sur la même connexion.
- RPO : faible
- RTO : faible
Avantages :
- les écritures sur les secondaires sont réalisées sans délai (le rejeu n’est par défaut pas immédiat, donc la donnée pourrait ne pas être immédiatement visible)
- le client sait si sa commande a réussi sur le serveur secondaire
Inconvénients :
- les écritures sont d’autant plus lentes qu’il y a de serveurs secondaires synchrones
- complexité de mise en oeuvre (architecture et configuration)
Pour aller plus loin :
- Support de formation PostgreSQL Sauvegardes et Réplication
- Formation Sauvegarde et Réplication avec PostgreSQL
- Prochaines dates de formation :
- 27-29 septembre 2022
- 17-21 octobre 2022
- 12-16 décembre 2022