Paris, le 6 septembre 2022

Avec plusieurs millions de sites web inaccessibles, l’incendie du datacenter strasbourgeois d’OVH le 10 mars 2021 est un évènement qui a marqué les esprits. Le réveil a été difficile pour les DSI concernées. Pour les autres, cela a été l’occasion de vérifier qu’elles ne pourront pas être impactées par un tel évènement.
C’est l’occasion de revenir sur les fondamentaux de la sauvegarde et de la restauration de vos instances PostgreSQL. Trop souvent, nos consultants rencontrent des clients qui ne prennent pas au sérieux leurs sauvegardes.
En informatique, la sauvegarde (backup en anglais) est l’opération qui consiste à dupliquer et à mettre en sécurité les données contenues dans un système informatique.
Pourquoi avoir une politique de sauvegarde/restauration ?
L’objectif essentiel de la sauvegarde est la sécurisation des données. Autrement dit, l’utilisateur cherche à se protéger d’une panne matérielle (perte d’un serveur, perte ou corruption d’un disque), d’un bug, d’une erreur humaine (un utilisateur supprime des données essentielles), voire d’une attaque (malveillance, ransomware…). La sauvegarde permet de restaurer les données perdues.
Il est important de définir dans votre organisation votre politique de sauvegarde :
- Que sauvegarder ? Autrement dit : peut-on se permettre de perdre certaines données ?
- À quelle fréquence ?
- Sur quels supports ?
- Avec quels outils ?
- Comment et quand vérifier ?
Enfin, il faut régulièrement tester une restauration, ne serait-ce que pour vérifier que la procédure est complète et facile à suivre. Ce n’est pas dans un moment d’urgence et de stress (le rafraîchissement des bases de test ou développement est l’occasion idéale) qu’on doit découvrir la procédure.
La règle des 3-2-1
Il est conseillé de suivre au moins la règle 3-2-1 :
- 3 exemplaires des données (au moins)
- dont 2 sur des médias différents
- dont 1 hors site (et hors ligne)
Les données originales elles-mêmes sont le premier exemplaire. Deux copies doivent se trouver sur des supports physiques différents, de préférence sur un autre serveur, pour parer à la destruction du support original, notamment une perte de disques durs. La première copie peut être à proximité pour faciliter une restauration. La dernière copie est stockée hors ligne.
En effet, l’un des points les plus importants à prendre en compte est l’endroit où sont stockés les fichiers des sauvegardes. Des sauvegardes sur la même machine sont vulnérables face à une défaillance matérielle ; elles peuvent être perdues en même temps que l’instance sauvegardée. Un incendie peut emporter aussi bien les bases de données que les serveurs où sont déportées les sauvegardes.
Même le cloud n’est pas magique : la sauvegarde reste susceptible de se trouver physiquement au même endroit que les données originales. L’incendie d’OVH Strasbourg est un cas extrême, mais il souligne l’importance de stocker au moins une sauvegarde sur un site différent. De plus, un ransomware peut s’attaquer aussi à des sauvegardes accessibles par le réseau. Des disques stockés permettent d’y parer, même si la mise à jour sera plus manuelle et moins fréquente. Ces différentes sauvegardes ne sont pas forcément assurées par les mêmes outils.
RPO/RTO :
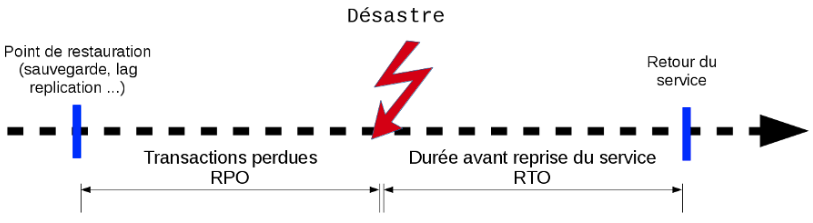
La politique de sauvegarde découle du :
- RPO (Recovery Point Objective) : Perte de Données Maximale Admissible faible ou importante ?
- RTO (Recovery Time Objective) : Durée Maximale d’Interruption Admissible courte ou longue ?
RPO
La RPO (ou PDMA) est la perte de données maximale admissible, ou quantité de données que l’on peut tolérer de perdre lors d’un sinistre majeur, souvent exprimée en heures ou minutes.
RPO importante
Pour un système mis à jour épisodiquement ou avec des données non critiques, ou facilement récupérables, la RPO peut être importante (par exemple une journée). Peuvent alors s’envisager des solutions comme :
- les sauvegardes logiques (pg_dump) ;
- les sauvegardes des fichiers à froid.
RPO faible
Dans beaucoup de cas, la perte de données admissible est très faible (moins de quelques minutes), voire nulle. Il faudra s’orienter vers des solutions de types :
- sauvegarde à chaud ;
- sauvegarde avec restauration à un point donnée dans le temps (PITR) ;
- secondaires en réplication asynchrone, voire synchrone.
RTO
La RTO (ou DMIA) est la durée maximale d’interruption du service.
RTO importante
Dans beaucoup de cas, les utilisateurs peuvent tolérer une indisponibilité de plusieurs heures, voire jours. La durée de reprise du service n’est alors pas critique, on peut utiliser des solutions simples comme :
- la restauration des fichiers ;
- la restauration d’une sauvegarde logique (dump).
RTO faible
Si la RTO est plus courte, le service doit très vite remonter. Cela nécessite des procédures avec un minimum d’acteurs et de manipulations :
- serveur existant en réplication ;
- solutions HA (Haute Disponibilité), c’est-à-dire avec bascule automatique.
Plus le besoin en RTO/RPO sera court, plus les solutions seront complexes à mettre en œuvre — et chères.
Inversement, pour des données non critiques, un RTO/RPO long permet d’utiliser des solutions simples et peu coûteuses. L’utilisateur doit être conscient que ces exigences imposent une charge à l’administration.
On peut utiliser plusieurs outils en parallèle. Ils répondent à différents types de sinistres et de RTO/RPO.
Nous reviendrons dans de prochains billets sur les différentes approches possibles en fonction de ces 2 critères de votre politique de sauvegarde.
Pour aller plus loin :
- Support de formation Politique de sauvegarde
- Formation Sauvegarde et Réplication avec PostgreSQL
- Prochaines dates de formation :
- 27-29 septembre 2022
- 17-21 octobre 2022
- 12-16 décembre 2022