Chambéry, le 29 Avril 2025
Vous connaissez peut-être explain.dalibo.com, l’outil pour visualiser et
comprendre les plans d’exécution générés par la commande EXPLAIN. Il accepte
des plans au format text et JSON.
Dans des versions précédentes de PostgreSQL, un bug entraînait la génération de
plans au format JSON invalides. Ce bug a été corrigé depuis longtemps, mais des
plans invalides sont toujours envoyés sur explain.dalibo.com (possiblement
générés avec une vieille version de PostgreSQL). Dans cet article, nous allons
découvrir combien sont concernés, et comment nous avons obtenu cette
information.
Le bug
Pour commencer, parlons du problème initial.
Il y a environ 6 ans (en août 2019), alors que j’étais en train de travailler sur PEV2 (le visualiseur de plans au cœur de explain.dalibo.com), j’ai trouvé et rapporté un bug dans PostgreSQL. Pour faire court, il y avait dans certains cas des clés dupliquées dans la structure JSON, ce qui considéré comme invalide.
Par exemple, dans le plan ci-dessous, la clé Workers est dupliquée :
[
{
...
"Plans": [
{
"Node Type": "Sort",
...
"Workers": [
{
"Worker Number": 0,
"Sort Method": "external merge",
...
}
],
"Workers": [
{
"Worker Number": 0,
"Actual Startup Time": 1487.846,
...
}
],
...
}
]
Analyser un plan comme celui-ci en utilisant JSON.parse(…) en Javascript ne
déclenche aucune erreur, mais ne garde qu’une seule des deux clés
dupliquées. Il en découle une perte d’information. Dans l’exemple ci-dessus, la
Sort Method serait oubliée.
Contournement
Comme JSON.parse() ne peut pas être utilisé directement, pour PEV2, j’ai
décidé de me reposer sur une bibliothèque tierce (clarinet) pour analyser le plan par flux (c’est à dire ligne par ligne) et prendre soin des clés dupliquées en fusionnant les valeurs.
Mais cette bibliothèque n’est plus maintenue et (parmi d’autres) a une dépendance sur stream pour gérer les flux Node.js dans le navigateur. Avoir trop de dépendances est un risque et celle-ci peut sembler superflue.
Bug corrigé
Par chance, le problème dans PostgreSQL a été corrigé en janvier 2020 (version 13).
Pour faciliter la maintenance de PEV2, j’ai donc envie de supprimer la dépendance. Cependant, j’ai aussi besoin d’être certain que ça ne sera pas au détriment des utilisateurs. La bonne question à laquelle il faut d’abord répondre est : « Combien d’utilisateurs utilisent encore une version de PostgreSQL affectée par le bug ? ». C’est quasiment impossible à savoir, mais je peux au moins répondre à la question : « Combien de plans contiennent des clés dupliquées ? ».
À la recherche de clés dupliquées
En avril 2025 (à peu près 6 ans après le lancement du site), un peu plus de 951 000 plans sont stockés dans la base de données utilisée pour explain.dalibo.com (~ 10 Gio). On peut considérer que c’est représentatif.
Nettoyage des sources
Les plans d’exécution peuvent être générés par un grand nombre d’outils différents avec différents paramètres d’affichage. Il y a donc une importante variété de rendus.
Voici quelques exemples de variantes quelque peu exotiques d’exports par
psql :
+----------------------------------------------------+
| QUERY PLAN |
+----------------------------------------------------+
| [ +|
| { +|
| "Plan": { +|
| "Node Type": "Nested Loop", +|
╔════════════════════════════════════════════════════╗
║ QUERY PLAN ║
╠════════════════════════════════════════════════════╣
║ [ ↵║
║ { ↵║
║ "Plan": { ↵║
║ "Node Type": "Nested Loop", ↵║
Pour savoir combien de plans sont au format JSON et ont des clés dupliquées, la
première étape consiste à supprimer les caractères d’encadrement, les titres et
autres informations extra. C’est fait en créant une fonction en PL/pgSQL
avec un lot d’expressions régulières pour remplacer les caractères inutiles.
CREATE OR REPLACE FUNCTION cleanup_source(source TEXT)
RETURNS TEXT AS $$
BEGIN
-- Remove frames around, handles |, ║,
source := REGEXP_REPLACE(source, E'^(\\||║|│)(.*)\\1\\r?\\n', E'\\2\n', 'gm');
-- Remove frames at the end of line, handles |, ║,
source := REGEXP_REPLACE(source, E'(.*)(\\||║|│)$\\r?\\n', E'\\1\n', 'gm');
-- Remove separator lines from various types of borders
source := REGEXP_REPLACE(source, E'^\\+-+\\+\\r?\\n', '', 'gm');
source := REGEXP_REPLACE(source, E'^(-|─|═)\\1+\\r?\\n', '', 'gm');
source := REGEXP_REPLACE(source, E'^(├|╟|╠|╞)(─|═)\\2*(┤|╢|╣|╡)\\r?\\n', '', 'gm');
-- Remove more horizontal lines
source := REGEXP_REPLACE(source, E'^\\+-+\\+\\r?\\n', '', 'gm');
source := REGEXP_REPLACE(source, E'^└(─)+┘\\r?\\n', '', 'gm');
source := REGEXP_REPLACE(source, E'^╚(═)+╝\\r?\\n', '', 'gm');
source := REGEXP_REPLACE(source, E'^┌(─)+┐\\r?\\n', '', 'gm');
source := REGEXP_REPLACE(source, E'^╔(═)+╗\\r?\\n', '', 'gm');
-- Remove quotes around lines, both ' and "
source := REGEXP_REPLACE(source, E'^([\\"\'])(.*)\\1\\r?', E'\\2', 'gm');
-- Remove "+" line continuations
source := REGEXP_REPLACE(source, E'\\s*\\+\\r?\\n', E'\n', 'gm');
-- Remove "↵" line continuations
source := REGEXP_REPLACE(source, E'↵\\r?', E'\n', 'gm');
-- Remove "query plan" header
source := REGEXP_REPLACE(source, E'^\\s*QUERY PLAN\\s*\\r?\\n', '', 'm');
-- Remove rowcount
-- example: (8 rows)
-- Note: can be translated
-- example: (8 lignes)
source := REGEXP_REPLACE(source, E'^\\(\\d+\\s+[a-z]*s?\\)(\\r?\\n|$)', E'\n', 'gm');
-- Replace two double quotes (added by pgAdmin)
source := REGEXP_REPLACE(source, E'""', '"', 'gm');
-- Remove double quotes at begining and end of plan
source := REGEXP_REPLACE(source, E'^\\"(.*)\\r?', '', 'gm');
source := REGEXP_REPLACE(source, E'^[^\\"]*\\"\\r?$', '', 'gm');
RETURN source;
END;
$$ LANGUAGE plpgsql;
Détection des clés dupliquées
La seconde étape consiste évidemment à détecter les clés dupliquées. Pour cela, la
meilleure option que j’ai trouvée a été de reposer sur PL/v8 pour faire
l’analyse du texte brut.
-- Create the v8 extension
CREATE EXTENSION plv8;
-- Create function to check if plan is JSON parsable
CREATE OR REPLACE FUNCTION is_json(json_text TEXT)
RETURNS BOOLEAN AS $$
try {
JSON.parse(json_text);
return true;
} catch (e) {
return false;
}
$$ LANGUAGE plv8 IMMUTABLE STRICT;
-- Create function to detect duplicate keys
CREATE OR REPLACE FUNCTION detect_json_duplicate_keys(json_text TEXT)
RETURNS TEXT[] AS $$
const duplicates = new Set();
const stack = [];
const keysStack = [];
const tokenizer = /[{}\[\]]|"(?:[^"\\]|\\.)*"(?=\s*:)/g;
let match;
let currentKeys = [];
while ((match = tokenizer.exec(json_text)) !== null) {
const token = match[0];
if (token === '{') {
// Start a new object scope
currentKeys.push(new Set());
} else if (token === '}') {
// End of an object scope
currentKeys.pop();
} else if (token === '[') {
// Just track arrays — doesn't affect key scope
stack.push('[');
} else if (token === ']') {
stack.pop();
} else if (token.startsWith('"')) {
const key = token.slice(1, -1).replace(/\\"/g, '"');
if (currentKeys.length > 0) {
const keySet = currentKeys[currentKeys.length - 1];
if (keySet.has(key)) {
duplicates.add(key);
} else {
keySet.add(key);
}
}
}
}
return Array.from(duplicates);
$$ LANGUAGE plv8 IMMUTABLE;
Mise à jour des données
Ensuite, ces fonctions sont utilisées dans une requête sur tous les
enregistrements de la table plans pour renseigner une nouvelle colonne
dédiée.
WITH updated_data AS (
SELECT
*,
cleanup_source(plan) AS cleaned
FROM plans
),
enriched_data AS (
SELECT
*,
is_json(cleaned) AS is_json,
detect_json_duplicate_keys(cleaned) AS dup_keys
FROM updated_data
)
UPDATE plans
SET duplicated_keys = u.dup_keys
FROM enriched_data u
WHERE t.id = u.id AND u.is_json IS TRUE;
Performance
Malheureusement, une telle requête aurait été extrêmement longue. Notamment, elle ne peut pas être parallélisée puisque PostgreSQL ne permet pas la parallélisation pour des requêtes d’écriture.
Par contre, grâce au fait que la table plans est divisée en partitions, il
est possible de faire une sorte de « parallélisation côté client » en lançant
la requête sur chaque partition dans un script bash.
Cela m’a même permis au passage de calculer et afficher la durée.
#!/bin/bash
START_TIME=$(date +%s)
for i in $(seq 0 49); do
echo "Start detection on partition $i"
psql -f detect.sql --set partition_table=plans.part_$i > /dev/null 2>&1 &
done
wait
END_TIME=$(date +%s)
echo "✅ Finished in $((END_TIME - START_TIME)) seconds."
Le script (qui dépend des processeurs et de leur nombre) a tourné pendant un peu plus de 6 heures.
Résultats
Après ça, j’ai simplement exécuté la requête SQL suivante :
SELECT
month,
filtered_count,
unfiltered_count,
SUM(filtered_count) OVER (ORDER BY month) AS total_filtered,
SUM(unfiltered_count) OVER (ORDER BY month) AS total_unfiltered,
SUM(json_count) OVER (ORDER BY month) AS total_json,
(100.0 * filtered_count / NULLIF(unfiltered_count, 0)) AS ratio_filtered
FROM (
SELECT
date_trunc('month', created)::date AS month,
COUNT(*) FILTER (WHERE duplicated_keys != '{}' AND duplicated_keys IS NOT NULL) AS filtered_count,
COUNT(*) AS unfiltered_count,
COUNT(*) FILTER (WHERE duplicated_keys IS NOT NULL) AS json_count
FROM
plans
GROUP BY
date_trunc('month', created)
) sub
ORDER BY
month;
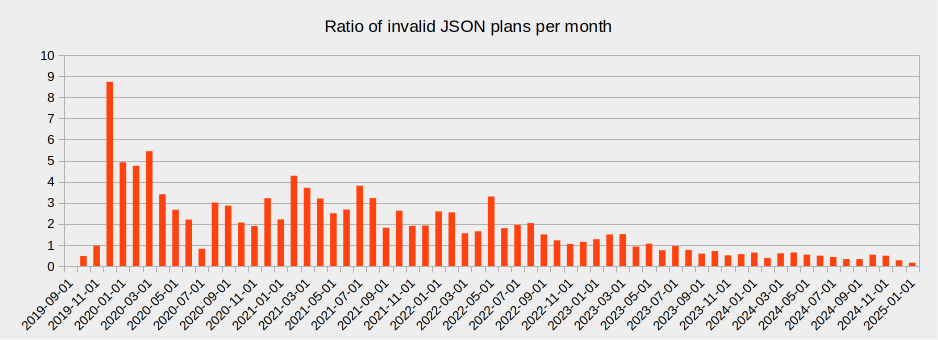
Un peu plus de 380 000 plans envoyés sont au format JSON (sur un total d’environ 950 000). 7 600 sont au format JSON et ont des clés dupliquées, ce qui représente moins de 0,8% du total. Sur les derniers 6 mois, c’est même 0,3% (670 à comparer à ~200 000). Et c’est en décroissance.
Le graphique suivant montre l’évolution de la proportion des plans avec des clés dupliquées en fonction du temps.
Politique de rétention des données
Nous conservons les plans que les utilisateurs envoient sur explain.dalibo.com, sauf s’ils les suppriment. Ceci uniquement dans le seul but d’améliorer PEV2 et notre connaissance de PostgreSQL, comme nous avons pu le voir dans cet article.
Si la confidentialité de vos requêtes est importante pour vous, vous pouvez toujours installer l’application Flask application sur votre réseau ou utiliser la version autonome pev2.html qui peut être utilisée localement sur votre navigateur.
Conclusion
Un petit nombre de plans envoyés sur explain.dalibo.com semble généré sur des clusters qui utilisent encore une version « buguée » de PostgreSQL, seulement moins de 3 pour 1000 ces derniers temps et il y en a de moins en moins. Cela donne une idée de la proportion de clusters pre-PG14 dans l’écosystème PostgreSQL, bien que beaucoup d’autres puissent être utilisés dans des cas où des optimisations ne sont plus tentées. Partant de ce constat, du fait que seulement une petite partie des informations sont perdues avec une analyse “standard” du JSON, et que PostgreSQL v13 sera en fin de support communautaire d’ici fin 2025, je pense qu’il est prudent de supprimer le support des clés dupliquées dans PEV2, et donc de supprimer la dépendance sur la bibliothèque tierce.