Chambéry, 29th April 2025
You may know explain.dalibo.com, the tool for visualizing and understanding execution plans generated with the EXPLAIN command. It accepts text and JSON formats.
In earlier versions of PostgreSQL, a bug caused the generation
of invalid JSON in execution plans. This bug was fixed a
while ago, but invalid plans are still submitted to explain.dalibo.com
(possibly generated with an old version of PostgreSQL). In this
article, we’ll discover how many and how I got this information.
The Bug
To begin with, let’s talk about the initial issue.
Almost 6 years ago (in August 2019), while I was working on PEV2 (the execution plan vizualizer at the heart of explain.dalibo.com), I found and reported a bug in PostgreSQL. In short, there were sometimes duplicated keys in the JSON structure, which is considered invalid.
For example, in the following plan, the Workers key is duplicated:
[
{
...
"Plans": [
{
"Node Type": "Sort",
...
"Workers": [
{
"Worker Number": 0,
"Sort Method": "external merge",
...
}
],
"Workers": [
{
"Worker Number": 0,
"Actual Startup Time": 1487.846,
...
}
],
...
}
]
Parsing a plan like this one using JSON.parse(…) in Javascript doesn’t
raise any error, but simply keeps only one of the duplicated keys.
We end up with information loss.
In the example above, the Sort Method
would be forgotten.
Workaround
Since JSON.parse() cannot be used directly, for PEV2, I decided to rely on a
third party library (clarinet) to stream-parse
the plan (ie. line by line) and take good care of the duplicated keys by
merging the values.
But this library is not maintained anymore and (among others) has a dependence on stream to handle Node.js streams in the browser. Having too many dependencies is a risk and this one is probably overkill anyways.
Bug solved
Fortunately, the issue in PostgreSQL got solved in January 2020 (for version 13).
Taking this into account, and for the sake of the maintenance of PEV2, I want to get rid of this dependency. But I need to make sure that this would not be at users’ expense. The good question to answer is: « How many users still run a version of PostgreSQL affected by the bug? ». This is almost impossible to know but I can at least give an answer to the question: « How many plans contain duplicated keys? ».
In the Search for Duplicated Keys
As of April 2025 (almost 6 years after the launch), a bit more than 951’000 plans are stored in the database for explain.dalibo.com (~10GB). This can be considered representative.
Source Cleanup
Execution plans may be generated by many different tools and with many different formatting settings. So there’s a large variety of renderings.
Here are a few examples of somewhat exotic variants of psql exports:
+----------------------------------------------------+
| QUERY PLAN |
+----------------------------------------------------+
| [ +|
| { +|
| "Plan": { +|
| "Node Type": "Nested Loop", +|
╔════════════════════════════════════════════════════╗
║ QUERY PLAN ║
╠════════════════════════════════════════════════════╣
║ [ ↵║
║ { ↵║
║ "Plan": { ↵║
║ "Node Type": "Nested Loop", ↵║
In order to know how many of those plans are in JSON format and have duplicated
keys, the first step is to remove any framing, headings or extra information.
This is done by creating a function in PL/pgSQL with a bunch of regular
expressions to replace the useless characters.
CREATE OR REPLACE FUNCTION cleanup_source(source TEXT)
RETURNS TEXT AS $$
BEGIN
-- Remove frames around, handles |, ║,
source := REGEXP_REPLACE(source, E'^(\\||║|│)(.*)\\1\\r?\\n', E'\\2\n', 'gm');
-- Remove frames at the end of line, handles |, ║,
source := REGEXP_REPLACE(source, E'(.*)(\\||║|│)$\\r?\\n', E'\\1\n', 'gm');
-- Remove separator lines from various types of borders
source := REGEXP_REPLACE(source, E'^\\+-+\\+\\r?\\n', '', 'gm');
source := REGEXP_REPLACE(source, E'^(-|─|═)\\1+\\r?\\n', '', 'gm');
source := REGEXP_REPLACE(source, E'^(├|╟|╠|╞)(─|═)\\2*(┤|╢|╣|╡)\\r?\\n', '', 'gm');
-- Remove more horizontal lines
source := REGEXP_REPLACE(source, E'^\\+-+\\+\\r?\\n', '', 'gm');
source := REGEXP_REPLACE(source, E'^└(─)+┘\\r?\\n', '', 'gm');
source := REGEXP_REPLACE(source, E'^╚(═)+╝\\r?\\n', '', 'gm');
source := REGEXP_REPLACE(source, E'^┌(─)+┐\\r?\\n', '', 'gm');
source := REGEXP_REPLACE(source, E'^╔(═)+╗\\r?\\n', '', 'gm');
-- Remove quotes around lines, both ' and "
source := REGEXP_REPLACE(source, E'^([\\"\'])(.*)\\1\\r?', E'\\2', 'gm');
-- Remove "+" line continuations
source := REGEXP_REPLACE(source, E'\\s*\\+\\r?\\n', E'\n', 'gm');
-- Remove "↵" line continuations
source := REGEXP_REPLACE(source, E'↵\\r?', E'\n', 'gm');
-- Remove "query plan" header
source := REGEXP_REPLACE(source, E'^\\s*QUERY PLAN\\s*\\r?\\n', '', 'm');
-- Remove rowcount
-- example: (8 rows)
-- Note: can be translated
-- example: (8 lignes)
source := REGEXP_REPLACE(source, E'^\\(\\d+\\s+[a-z]*s?\\)(\\r?\\n|$)', E'\n', 'gm');
-- Replace two double quotes (added by pgAdmin)
source := REGEXP_REPLACE(source, E'""', '"', 'gm');
-- Remove double quotes at begining and end of plan
source := REGEXP_REPLACE(source, E'^\\"(.*)\\r?', '', 'gm');
source := REGEXP_REPLACE(source, E'^[^\\"]*\\"\\r?$', '', 'gm');
RETURN source;
END;
$$ LANGUAGE plpgsql;
Duplicated Keys Detection
The second step is obviously to detect the duplicated keys. For that matter,
the best option I found was to rely on PL/v8 to do raw text parsing.
-- Create the v8 extension
CREATE EXTENSION plv8;
-- Create function to check if plan is JSON parsable
CREATE OR REPLACE FUNCTION is_json(json_text TEXT)
RETURNS BOOLEAN AS $$
try {
JSON.parse(json_text);
return true;
} catch (e) {
return false;
}
$$ LANGUAGE plv8 IMMUTABLE STRICT;
-- Create function to detect duplicate keys
CREATE OR REPLACE FUNCTION detect_json_duplicate_keys(json_text TEXT)
RETURNS TEXT[] AS $$
const duplicates = new Set();
const stack = [];
const keysStack = [];
const tokenizer = /[{}\[\]]|"(?:[^"\\]|\\.)*"(?=\s*:)/g;
let match;
let currentKeys = [];
while ((match = tokenizer.exec(json_text)) !== null) {
const token = match[0];
if (token === '{') {
// Start a new object scope
currentKeys.push(new Set());
} else if (token === '}') {
// End of an object scope
currentKeys.pop();
} else if (token === '[') {
// Just track arrays — doesn't affect key scope
stack.push('[');
} else if (token === ']') {
stack.pop();
} else if (token.startsWith('"')) {
const key = token.slice(1, -1).replace(/\\"/g, '"');
if (currentKeys.length > 0) {
const keySet = currentKeys[currentKeys.length - 1];
if (keySet.has(key)) {
duplicates.add(key);
} else {
keySet.add(key);
}
}
}
}
return Array.from(duplicates);
$$ LANGUAGE plv8 IMMUTABLE;
Update Data
Then those functions are used in a query executed on all records of the plans
table to populate a new dedicated column.
WITH updated_data AS (
SELECT
*,
cleanup_source(plan) AS cleaned
FROM plans
),
enriched_data AS (
SELECT
*,
is_json(cleaned) AS is_json,
detect_json_duplicate_keys(cleaned) AS dup_keys
FROM updated_data
)
UPDATE plans
SET duplicated_keys = u.dup_keys
FROM enriched_data u
WHERE t.id = u.id AND u.is_json IS TRUE;
Performance
Unfortunately, this would have been extremely long and can’t be parallelized because PostgreSQL hasn’t added support for parallelization for write queries.
However, thanks to the fact that the plans table is split into partitions, it is
possible to do a kind of “client parallelization” by running the query on each
partition in a bash script.
I could even compute and display the total time spent.
#!/bin/bash
START_TIME=$(date +%s)
for i in $(seq 0 49); do
echo "Start detection on partition $i"
psql -f detect.sql --set partition_table=plans.part_$i > /dev/null 2>&1 &
done
wait
END_TIME=$(date +%s)
echo "✅ Finished in $((END_TIME - START_TIME)) seconds."
The script is CPU-bound and ran for a bit more that 6 hours on my desktop computer.
Results
After that, we just run this SQL query:
SELECT
month,
filtered_count,
unfiltered_count,
SUM(filtered_count) OVER (ORDER BY month) AS total_filtered,
SUM(unfiltered_count) OVER (ORDER BY month) AS total_unfiltered,
SUM(json_count) OVER (ORDER BY month) AS total_json,
(100.0 * filtered_count / NULLIF(unfiltered_count, 0)) AS ratio_filtered
FROM (
SELECT
date_trunc('month', created)::date AS month,
COUNT(*) FILTER (WHERE duplicated_keys != '{}' AND duplicated_keys IS NOT NULL) AS filtered_count,
COUNT(*) AS unfiltered_count,
COUNT(*) FILTER (WHERE duplicated_keys IS NOT NULL) AS json_count
FROM
plans
GROUP BY
date_trunc('month', created)
) sub
ORDER BY
month;
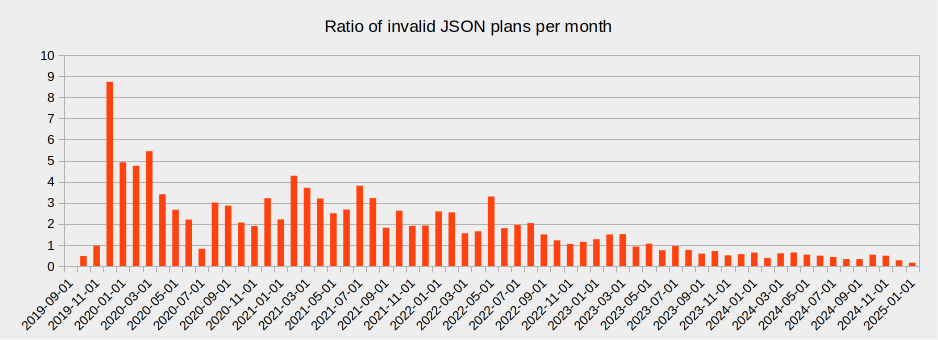
A bit more than 380’000 submitted plans are in JSON format (~950’000 in total). ~7’600 are in JSON and have duplicated keys, which is less than 0.8% of total. For the last 6 months, it’s even ~0.3% (670 compared to ~200’000). And it’s decreasing.
The following chart shows the evolution of the proportion of plans with duplicated keys over time.
Data retention policy
We store the plans that users post to explain.dalibo.com, unless they delete them. And only to improve PEV2 or increase our knowledge of PostgreSQL, as we saw it in this article.
If confidentiality matters, you can install the Flask application on your network or use the pev2.html standalone version locally in your browser.
Conclusion
A few plans submitted to explain.dalibo.com seem generated on clusters that still run a « buggy » version of PostgreSQL. However, it’s only a very small fraction (less than 3 out of 1000) lately and there are fewer and fewer. This gives an hint of the proportion of pre-PG14 clusters in the PostgreSQL ecosystem, although many more may run where no optimization is attempted anymore.
Given that, the fact that only a small amount of information is lost with a “standard” JSON parsing, and that PostgresSQL v13 will reach EOL end of 2025, I think it is safe to remove the support for handling duplicated keys in PEV2, thus remove the dependency on the third-party library.