Vallée de Munster, 13 février 2025
Récemment, Dalibo a été sollicité par un client pour réaliser une étude sur l’exploitation de PostgreSQL dans Kubernetes. Ce client avait légitimement des questions concernant le stockage pour PostgreSQL. Ce dernier nous a explicitement demandé notre avis concernant Longhorn, une solution de stockage répliqué et distribué pour Kubernetes.
Bien que nous ayons quelques hypothèses à ce sujet, la solution a
suscité notre intérêt. Nous avons donc voulu évaluer/explorer cette
solution de stockage de manière approfondie. Nous vous proposons dans
cet article une présentation de Longhorn, mais aussi d’une partie des
tests que nous avons réalisés pour PostgreSQL sur ce type
d’architecture. Ce sera l’occasion d’évoquer succinctement l’utilisation
du plugin kubectl de l’opérateur CloudNativePG, ce plugin sera utilisé
pour lancer fio et pgbench dans un environnement conteneurisé.

Présentation Longhorn
Longhorn est une solution de stockage (block storage) persistant dite hautement disponible et distribuée pour les Kubernetes.
Cette solution intègre des fonctionnalités de synchronisation des données, de prise d’instantané et de sauvegarde incrémentielle des volumes.
Longhorn permet entre autre :
- La réplication du stockage entre plusieurs nœuds Kubernetes ;
- La mise en place d’un stockage type “hyperconvergé”, le stockage se fait par dessus Kubernetes. Il est par exemple possible de combiner des nœuds de calcul et de stockage ;
- De facilement exporter les données vers du stockage de type S3 ou NFS. Pour par exemple stocker et planifier des sauvegardes ;
- D’effectuer des instantanés (snapshot) ;
- D’avoir une interface web de gestion.
Installation de Longhorn
Nous avons réalisé une installation de base de Longhorn en utilisant la procédure suivante:
-
Appliquer le manifest distribué par le projet :
$ kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/v1.8.0/deploy/longhorn.yaml -
Vérifier la présence des composants pour le fonctionnement de base dans l’espace de nom
longhorn-system:$ kubectl get pods --namespace longhorn-system NAME READY STATUS RESTARTS AGE csi-attacher-79866cdcf8-bs22m 1/1 Running 1 (11m ago) 12m ... longhorn-driver-deployer-64c9779f48-v4t55 1/1 Running 0 19m longhorn-manager-xds9c 2/2 Running 0 19m longhorn-ui-5677d74dfd-c97p7 1/1 Running 0 19m longhorn-ui-5677d74dfd-dcckd 1/1 Running 0 19m $ kubectl get deployments --namespace longhorn-system NAME READY UP-TO-DATE AVAILABLE AGE csi-attacher 3/3 3 3 19m csi-provisioner 3/3 3 3 19m csi-resizer 3/3 3 3 19m csi-snapshotter 3/3 3 3 19m longhorn-driver-deployer 1/1 1 1 25m longhorn-ui 2/2 2 2 25 $ kubectl get services --namespace longhorn-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE longhorn-admission-webhook ClusterIP 10.96.9.151 <none> 9502/TCP 31m ... longhorn-recovery-backend ClusterIP 10.96.235.98 <none> 9503/TCP 31m -
Vérifier la présence des deux classes de stockage définies par le manifest de Longhorn
$ kubectl get storageclasses.storage.k8s.io NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE longhorn (default) driver.longhorn.io Delete Immediate true 16m longhorn-static driver.longhorn.io Delete Immediate true 16m -
Et pour finir, consulter l’interface de gestion (nous utilisons ici, une simple redirection de port) :
$ kubectl port-forward services/longhorn-frontend -n longhorn-system 8080:80Nous pouvons maintenant ouvrir l’interface de gestion dans notre navigateur http://127.0.0.1:8080
Nous avons maintenant un cluster Kubernetes en mesure d’utiliser du stockage distribué. L’utilisation de Longhorn permet potentiellement de réduire le risque de perdre des données lors de la perte d’un nœud Kubernetes. L’interface web de gestion donne un bref aperçu des nombreuses options offertes par cette solution de stockage. Pour plus des informations complémentaires concernant les fonctionnalités, le fonctionnement interne de et la réplication inter nœud, nous vons invitons à consulter la documentation officielle du projet.
Avant de continuer, il nous semble utile de rappeler que notre installation (de Longhorn) est uniquement pour des tests. Pour un système de production, il est strictement nécessaire de se questionner concernant divers sujets que nous n’aborderons pas ici (par exemple: CAP, fencing, sauvegarde…).
Après ces quelques vérifications et un rapide tour de l’interface de gestion, nous pouvons démarrer nos tests.
Tester avec du stockage répliqué
Dans ce paragraphe, nous allons mesurer la charge disque que Longhorn
est capable d’encaisser avec un volume composé de 3 réplicas
(configuration fournie par défaut). Nous lancerons aussi quelques tests
avec pgbench sur une instance PostgreSQL. Comme annoncé dans
l’introduction, nous utiliserons pour cela le plugin
CNPG
pour kubectl. Pour finir, l’opérateur CNPG sera aussi utilisé pour nous
faciliter la création de nos instances PostgreSQL de tests.
Lancer fio
Avant d’effectuer nos tests avec PostgreSQL, nous allons utiliser fio
pour évaluer les performances brutes de notre stockage.
Pour cela, nous pouvons lancer la commande suivante :
$ kubectl cnpg fio fio-test-perf -n default \
--pvcSize 2Gi --storageClass longhorn --dry-run |\
sed -e 's/runtime=60/runtime=3600/g'|kubectl apply -f -
Cette commande va exécuter fio pendant une heure avec un volume
dédié de 2 Gi. En fin d’exécution, les résultats sont récupérables via
une page web. Il est possible de consulter cette page en exposant le
service dédié :
$ kubectl port-forward -n fio deployment/fio-test-perf 8000
$ open http://127.0.0.1:8000
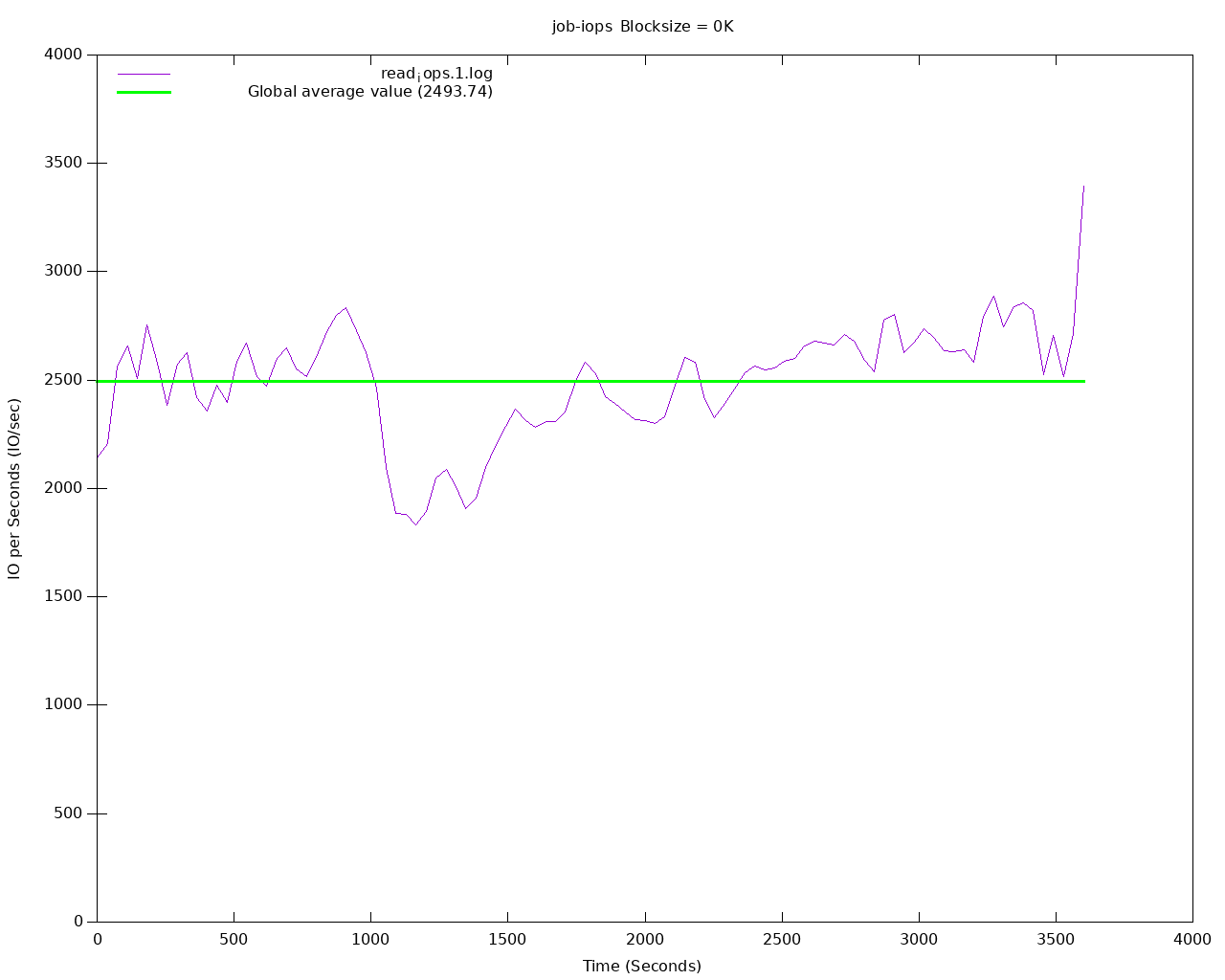
La page (consultable sur http://127.0.0.1:8000) présente des
graphiques et les logs de fio. Pour nos tests sur du stockage
répliqué la bande passante moyenne mesurée est de 2800 IOPs en
lecture :
Pour mesurer la capacité théorique en écriture, nous pouvons relancer
notre test en utilisant le scénario write de fio. Pour modifier les
différents paramètres de fio, nous exportons le manifest généré avec
le plugin CloudNativePG de kubectl pour ensuite le modifier :
$ kubectl cnpg fio fio-test-perf-write -n default --pvcSize 2Gi \
--storageClass longhorn --dry-run > /tmp/scenario.yaml
On modifie la ConfigMap pour fio qui se trouve dans le fichier
/tmp/scenario.yaml (on change à minima l’option rw de read a
write) :
apiVersion: v1
kind: ConfigMap
metadata:
name: fio-test-perf
namespace: default
data:
job: |-
[write]
direct=1
bs=8k
size=1G
time_based=1
runtime=3600
ioengine=libaio
iodepth=32
end_fsync=1
log_avg_msec=1000
directory=/data
rw=write
write_bw_log=read
write_lat_log=read
write_iops_log=read
...
L’exécution de ce scénario génère le graphique suivant :
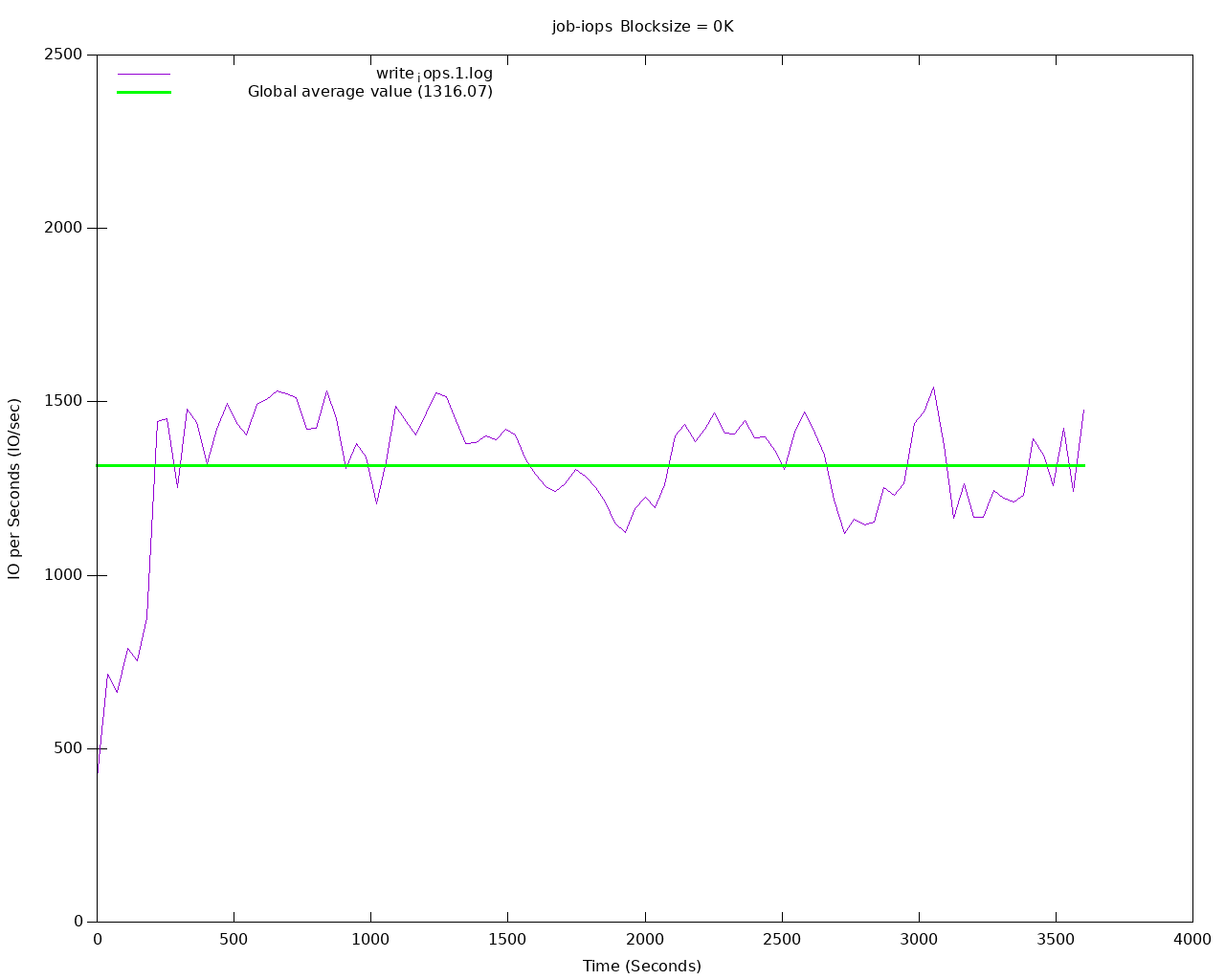
Nous pouvons conclure que Longhorn avec 3 réplicas sur notre infrastructure de test peut encaisser :
- 2819 IOPs en lecture
- 1316 IOPs en écriture
Tester avec une instance PostgreSQL
Nous allons maintenant utiliser pgbench sur un cluster PostgreSQL. Ce
cluster sera composé d’une seule instance PostgreSQL. Les données de
notre instance se trouveront sur du stockage répliqué sur 3 nœuds
Kubernetes (configuration de base de la classe de stockage longhorn).
Nous commençons par déclarer une instance avec la classe de stockage
longhorn :
$ kubectl apply -f - <<EOF
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cluster-longhorn
spec:
instances: 1
storage:
storageClass: longhorn
size: 10Gi
resources:
requests:
memory: 1Gi
cpu: '1'
limits:
memory: 2Gi
cpu: '2'
postgresql:
parameters:
shared_buffers: 256MB
effective_io_concurrency: '300'
random_page_cost: '1.1'
EOF
Cette instance (après initialisation) est utilisable et testable en suivant les étapes suivantes :
-
Garnir la base
appde notre instance avecpgbench. Pour cette opération, nous utilisons le pluginkubectlde CloudNativePG pour déployer unJob(job-instance-longhornici) dédié àpgbench. Les options--initialize--scale 250sont placées après un double tiret. En fonction de nos besoins, il est possible d’ajouter des options complémentaires pourpgbench:$ kubectl cnpg pgbench \ --job-name job-instance-longhorn cluster-longhorn \ -- --initialize --scale 250 -
Surveiller le
Podcorrespondant àpgbench(job-instance-longhorn-djgwb) :$ kubectl get pods NAME READY STATUS RESTARTS AGE cluster-longhorn-1 1/1 Running 0 8m34s cluster-longhorn-1-initdb-6bgsb 0/1 Completed 0 9m job-instance-longhorn-djgwb 1/1 Running 0 3m33s -
Récupérer les résultats de
pgbenchen affichant les journaux duJob:$ kubectl logs -f --namespace default job/job-instance-longhorn-client1 dropping old tables... NOTICE: table "pgbench_accounts" does not exist, skipping NOTICE: table "pgbench_branches" does not exist, skipping NOTICE: table "pgbench_history" does not exist, skipping NOTICE: table "pgbench_tellers" does not exist, skipping creating tables... generating data (client-side)... 100000 of 25000000 tuples (0%) of pgbench_accounts done (elapsed 0.08 s, remaining 20.13 s) 200000 of 25000000 tuples (0%) of pgbench_accounts done (elapsed 0.14 s, remaining 17.49 s) ... 24900000 of 25000000 tuples (99%) of pgbench_accounts done (elapsed 200.00 s, remaining 0.80 s) 25000000 of 25000000 tuples (100%) of pgbench_accounts done (elapsed 201.36 s, remaining 0.00 s) vacuuming... creating primary keys... done in 336.58 s (drop tables 0.01 s, create tables 0.14 s, client-side generate 203.41 s, vacuum 13.16 s, primary keys 119.86 s). -
Les informations utiles se trouvent à la fin :
- durée : 336.58 s
- temps création des clés primaires : 119.86 s
- client-side generate - principalement temps pour garnir les tables : 203.41 s
-
Si nécessaire, nous pouvons aussi récupérer la taille (3746 MB) de la base en utilisant cette commande :
$ kubectl exec --namespace=default --stdin --tty \ -ti cluster-longhorn-1 \ -- psql -c "SELECT pg_size_pretty(pg_database_size('app'))" Defaulted container "postgres" out of: postgres, bootstrap-controller (init) pg_size_pretty ---------------- 3746 MB (1 row) -
Maintenant que notre base de test est en place, nous lançons successivement des tâches (
Job) pourpgbenchen augmentant progressivement la valeur de l’option--client(et ce afin d’établir le tableau visible plus bas) :$ kubectl cnpg pgbench \ --job-name job-instance-longhorn-client1 cluster-longhorn \ -- --time 300 --client 1 --jobs 1 job/job-instance-longhorn-client1 create$ kubectl logs -f job/job-instance-longhorn-client1Cette dernière étape permet d’établir ce tableau (variation de l’option
--client) :--clientTPS Latence moyenne initial connection time 1 52 18.906 28.819 2 109 18.260 22.341 4 201 19.850 24.132 8 313 24.256 108.819 16 409 39.026 57.023
Tester avec du stockage non répliqué
Dans cette section, nous allons réaliser notre batterie de tests (Job
fio et plusieurs exécutions de pgbench) en utilisant du stockage non
répliqué.
On commence par ajouter une classe de stockage utilisant Longhorn en
positionnant le nombre de réplica à 1 (la partie importante est la ligne
numberOfReplicas: "1") :
$ kubectl apply -f - <<EOF
---
allowVolumeExpansion: true
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: longhorn-noreplica
parameters:
dataEngine: v1
dataLocality: disabled
disableRevisionCounter: "true"
fromBackup: ""
fsType: ext4
numberOfReplicas: "1"
staleReplicaTimeout: "30"
unmapMarkSnapChainRemoved: ignored
provisioner: driver.longhorn.io
reclaimPolicy: Delete
volumeBindingMode: Immediate
EOF
Nous pouvons vérifier la présence de cette nouvelle classe et reprendre nos tests en adaptant la classe de stockage :
$ kubectl get storageclasses.storage.k8s.io longhorn-noreplica
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
longhorn-noreplica driver.longhorn.io Delete Immediate true 4d
Lancer fio
On lance un nouveau Job pour fio en spécifiant notre nouvelle classe
de stockage :
$ kubectl cnpg fio fio-test-perf-noreplica -n default \
--pvcSize 2Gi --storageClass longhorn-noreplica --dry-run |\
sed -e 's/runtime=60/runtime=3600/g' | kubectl apply -f -
Pour ensuite consulter les résultats, on expose le port 80 de notre déploiement :
$ kubectl port-forward deployment/fio-test-perf-noreplica 8000
Et exécuter le test en écriture et consulter les résultats :
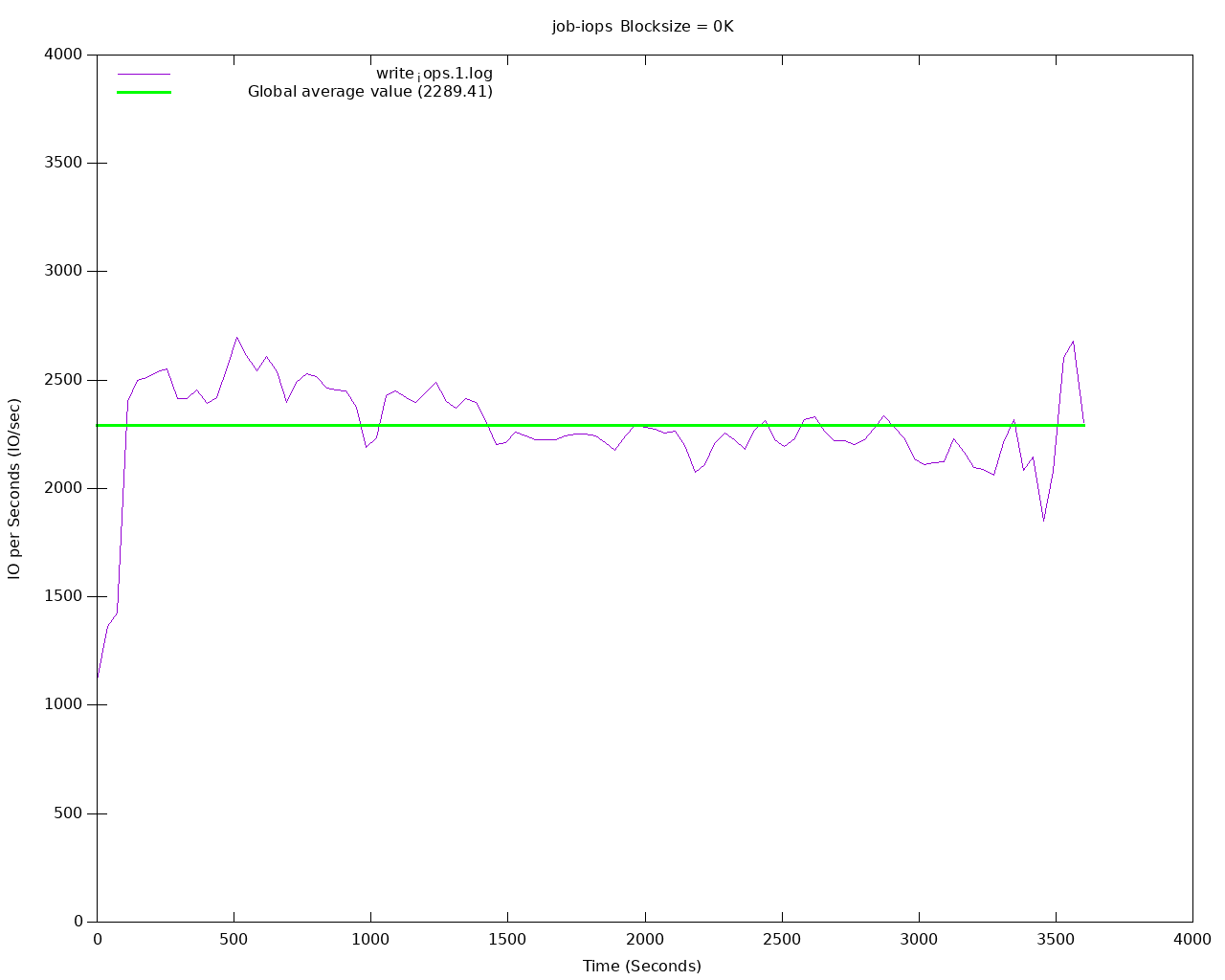
Nous constatons que notre solution de stockage configurée sans réplication est en mesure d’encaisser en moyenne :
- 2493 IOPs en lecture
- 2289 IOPs en écriture
Par rapport à une instance utilisant du stockage répliqué, on remarque une différence importante pour les écritures (presque 1000 IOPS en plus).
Tester avec une instance PostgreSQL
Après avoir testé avec fio, nous allons réaliser la même batterie de
tests avec pgbench que pour notre première instance.
On commence par déclarer une nouvelle instance PostgreSQL en utilisant notre nouvelle classe de stockage, pour ensuite :
- Garnir cette seconde instance avec
pgbenchet les options--initializeet--scale 250 - Lancer plusieurs tâches pour simuler progressivement 1, 2, 4, 8 et 16 clients PostgreSQL.
Ce qui va nous permettre de comparer les deux configurations avec et sans réplication synchrone au niveau stockage.
Le résultat du garnissage d’une base indique ceci :
$ kubectl logs -f jobs/job-instance-longhorn-noreplica
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
100000 of 25000000 tuples (0%) of pgbench_accounts done (elapsed 0.06 s, remaining 15.69 s)
200000 of 25000000 tuples (0%) of pgbench_accounts done (elapsed 0.31 s, remaining 37.95 s)
300000 of 25000000 tuples (1%) of pgbench_accounts done (elapsed 0.39 s, remaining 31.78 s)
24900000 of 25000000 tuples (99%) of pgbench_accounts done (elapsed 100.51 s, remaining 0.48 s)
25000000 of 25000000 tuples (100%) of pgbench_accounts done (elapsed 100.58 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done in 203.71 s (drop tables 0.01 s, create tables 0.09 s, client-side generate 102.00 s, vacuum 11.99 s, primary keys 89.62 s).
Ces informations nous montrent que sans réplication le garnissage de notre base prend approximativement 1/3 de temps en moins :
- durée : 203.71 s (336.58 s lors de notre première exécution)
- temps création des clés primaires : 89.62 s, (cela représente 30 s de moins que pour une instance avec du stockage répliqué)
- client-side generate - (principalement du temps pour garnir les tables) : 102.00 secondes, ce qui correspond à 101 secondes de moins que notre première instance avec du stockage répliqué
Et les résultats des différents jobs avec pgbench, nous permettent
d’établir le tableau suivant :
--client |
TPS | Latence moyenne | initial connection time |
|---|---|---|---|
| 1 | 63 | 13.953 | 19.090 |
| 2 | 144 | 13.864 | 43.447 |
| 4 | 242 | 19.433 | 25.395 |
| 8 | 329 | 24.300 | 138.927 |
| 16 | 412 | 38.839 | 157.923 |
Les lectures restent sensiblement identiques. Il pourrait être utile de vérifier le comportement du cache ou des caches (PostgreSQL, système…) pour en savoir plus concernant les lectures.
Conclusion - Stockage distribué avec PostgreSQL
Intuitivement, sur la base de notre connaissance d’autres solutions de stockage et du fonctionnement de PostgreSQL, on aurait tendance à conseiller de désactiver la réplication au niveau du stockage pour laisser PostgreSQL s’occuper de la réplication.
Les résultats de nos tests (pgbench lors des phases d’initialisations)
démontrent un impact (Write amplification) notable sur les écritures.
D’ailleurs, on retrouve dans la documentation de CloudNativePG un paragraphe spécifique concernant ce type de solution.
Most block storage solutions in Kubernetes, such as Longhorn and Ceph, recommend having multiple replicas of a volume to enhance resiliency. This approach works well for workloads that lack built-in resiliency.
However, CloudNativePG integrates this resiliency directly into the Postgres Cluster through the number of instances and the persistent volumes attached to them, as explained in “Synchronizing the state”.
As a result, defining additional replicas at the storage level can lead to write amplification, unnecessarily increasing disk I/O and space usage.
https://cloudnative-pg.io/documentation/1.25/storage/
Nos tests et la documentation valident donc nos intuitions. Lors de l’utilisation de PostgreSQL sur des technologies de stockage avancées, il est souvent souhaitable de s’appuyer sur les mécanismes natifs (de PostgreSQL) pour gérer la réplication. Dit plus simplement Longhorn, dans sa configuration de base, ne nous semble pas adapté pour notre SGBD favori et pourrait même avoir des effets indésirables.
Concernant les lectures disque, on constate que Longhorn, de par son architecture, n’apporte pas grand-chose pour PostgreSQL. Lors de nos tests, c’est surtout le cache système et de PostgreSQL qui semblent être bénéfiques. On aurait d’ailleurs pu présenter des tests spécifiques pour démontrer cela (pourquoi pas dans un prochain article ?!).
Cet article, nous a permis de présenter quelques fonctionnalités
fournies avec le plugin kubectl de CloudNativePG. Nous avons aussi un
bref aperçu du fonctionnement de Longhorn. Dans le cadre de nos
recherches et tests, nous avons traité plus en profondeur cette
technologie. Nous avons retenu ici, la partie la plus pertinente pour
PostgreSQL. D’autres articles concernant PostgreSQL et Kubernetes
arriveront prochainement sur notre blog.