Lyon, le 17 janvier 2025
CloudNativePG ou comment embarquer un éléphant sur un porte-conteneurs !
Dans le dernier article, nous avons vu comment déployer l’opérateur et comment
il réagissait lorsque le primaire disparaissait, avec notamment la bascule
automatique sur le secondaire. Regardons aujourd’hui ce que sont les Services
et quel est leur impact sur les connexions existantes lors d’une bascule.

Objets automatiquement créés
Avant toute chose, il est bon de savoir que l’opérateur va automatiquement créer
des ressources Kubernetes. Certaines sont créées lors de l’installation, lui
permettant de fonctionner ou de proposer de nouvelles fonctionnalités. C’est ce
que nous avons vu par exemple avec les Custom Resource Definition qui étendent
l’API initiale de Kubernetes.
D’autres ressources sont quant à elles créées lors de
la création d’une instance PostgreSQL. Nous l’avons vu par exemple avec la
commande kubectl get pod qui nous retournait deux lignes correspondant à deux
Pods. Pour n’en citer que quelques-unes : Pod, Secret, ConfigMap … et
des Services.
Qu’est-ce qu’un Service ?
Tout d’abord, un Pod est volatile par définition et lorsqu’il est
recréé, il obtient une nouvelle adresse IP. Comment un client (i.e application)
pourrait-il accéder de manière pérenne à ce Pod (par exemple, une instance
PostgreSQL) alors que l’adresse IP change ? On pourrait imaginer passer par une
résolution DNS, avec la modification de l’adresse IP, mais encore faut-il que
l’actualisation DNS se fasse assez rapidement…
Un Service se charge d’acheminer les connexions clientes vers l’application
demandée. Les clients se connectent donc à ce composant et ce dernier choisit
où transmettre le flux réseau en se basant sur des labels positionnés sur
le ou les Pods concernés.
Ainsi, un Service est donc plus “stable” dans le temps qu’un Pod. Nos
clients (i.e applications) peuvent donc utiliser son nom DNS (ou l’adresse IP)
pour accéder aux applications. Je vous renvoie sur la documentation Kubernetes
pour découvrir ce qu’est un Service et les différents types qui existent.
CloudNativePG crée trois services pour chaque cluster PostgreSQL déployé. Par exemple, pour le cluster que nous avons déployé la dernière fois, il existe :
- un service qui permet d’accéder au primaire, en lecture/écriture :
postgresql-rw; - un service qui permet d’accéder uniquement au(x) secondaire(s), en lecture seule :
postgresql-ro; - un service qui permet d’accéder à toutes les instances :
postgresql-r.
La pratique vaut souvent plus qu’un long discours. Regardons cela avec notre cluster PostgreSQL précédent et l’application pgAdmin4.
Déploiement de pgAdmin4
Pour vous montrer le principe, je vais utiliser l’application pgAdmin4 en la
déployant dans Kubernetes. Voici un ficher yaml qui permet de déployer pgAdmin4.
apiVersion: apps/v1
kind: Deployment
metadata:
name: pgadmin
spec:
replicas: 1
selector:
matchLabels:
app: pgadmin
template:
metadata:
labels:
app: pgadmin
spec:
containers:
- name: pgadmin
image: dpage/pgadmin4
ports:
- containerPort: 80
env:
- name: PGADMIN_DEFAULT_EMAIL
value: admin@example.com
- name: PGADMIN_DEFAULT_PASSWORD
value: admin
Lorsque pgAdmin4 est déployé, je l’expose avec la commande kubectl port-forward.
Cela me permet d’atteindre l’interface web depuis mon navigateur en allant sur
http://localhost:7777.
kubectl port-forward --address 0.0.0.0 $(kubectl get pod -o name | grep pgadmin) 7777:80
Je me connecte …
… et peux renseigner une nouvelle connexion :
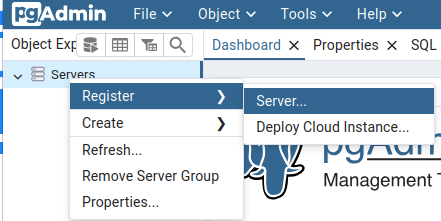
- Name : postgresql (Onglet General) ;
- Host name/address : postgresql-rw (Onglet Connection) ; C’est le nom (DNS) du Service créé par CloudNativePG
- Port : 5432 ;
- Username : app;
- Password :
- Il doit être récupéré directement depuis le
Secretpostgresql-app, avec par exemple, la commande suivante :kubectl get secret postgresql-app -o json | jq -r '.data.password' | base64 -d CVDVkYhMuKwH4Zg1xgESOSknA3R8Jet7en36NeyRdOoNT5WpBoWYBs0xccNMKO1HEn combinant plusieurs outils, je récupère le mot de passe du rôle
appdans leSecretpostgresql-appau format JSON. L’outiljq, véritable couteaux suisse de la manipulation de données au format JSON, permet d’extraire la valeur de la clé.data.password. Celle-ci étant encodée en Base64, j’utilise donc l’outilbase64pour le décoder.
- Il doit être récupéré directement depuis le
pgAdmin4 me permet d’accéder à l’instance primaire de mon cluster PostgreSQL. Je peux par exemple créer une table.
app=# create table a2 (i int);
CREATE TABLE
Prenons un peu de recul et faisons un rapide bilan :
- Deux instances PostgreSQL existent (une primaire et une secondaire);
- L’application pgAdmin4 est déployée dans le cluster ;
- J’ai renseigné le DNS du
ServiceKubernetes que CloudNativePG a créé pour moi ; - Je sais aussi que j’ai bien atteint l’instance primaire puisque j’ai pu créer une table (écrire).
Schématiquement, nous sommes dans la situation suivante,
où l’application pgAdmin4 pointe bien sur l’instance primaire postgresql-2 via
le Service postgresql-rw.
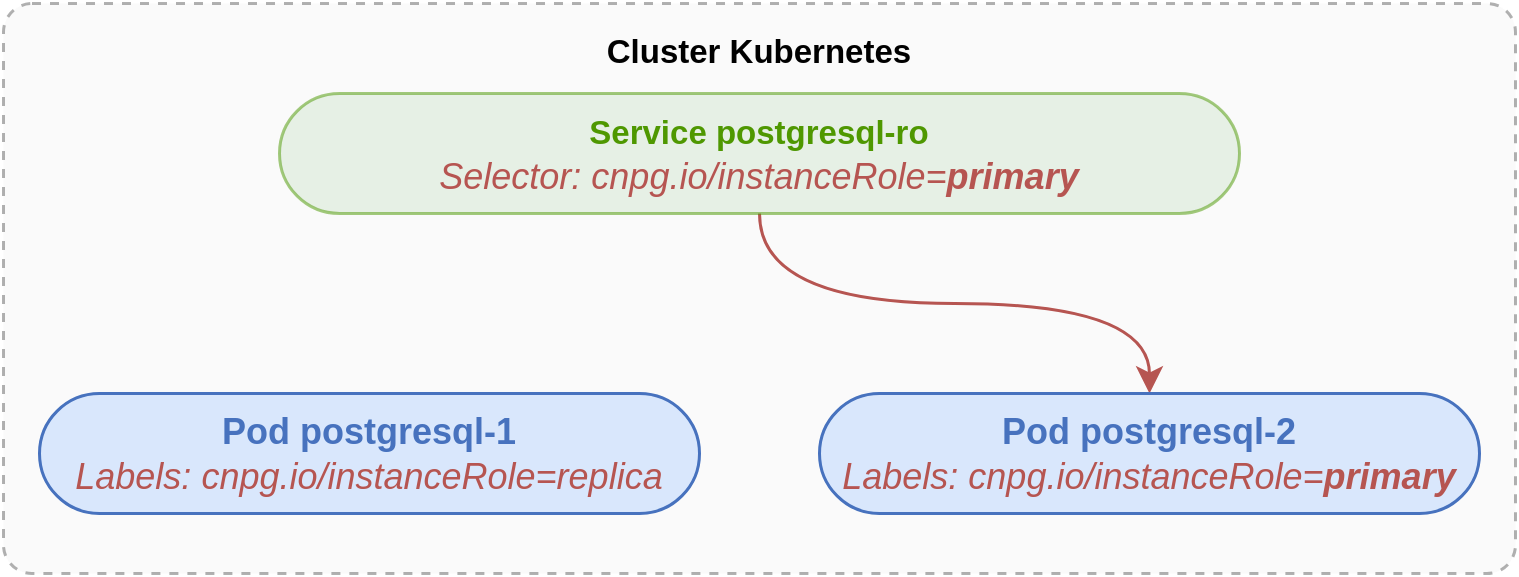
Mais … comment est-ce que le Service sait sur quelle instance rediriger le trafic ?
(Indice : c’est écrit en rouge sur le schéma 😊)
Le rôle des labels
À chaque instance est associé un ou plusieurs labels. Celui qui nous intéresse
particulièrement est cnpg.io/instanceRole. Chaque pod PostgreSQL possède
ces labels, ils sont ajoutés automatiquement par l’opérateur CloudNativePG.
La commande suivante montre, via le label, que c’est bien l’instance
postgresql-2 qui est primaire.
kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
[...]
postgresql-1 1/1 Running 0 48m cnpg.io/cluster=postgresql,cnpg.io/instanceName=postgresql-1,cnpg.io/instanceRole=replica,cnpg.io/podRole=instance,role=replica
postgresql-2 1/1 Running 0 63m cnpg.io/cluster=postgresql,cnpg.io/instanceName=postgresql-2,cnpg.io/instanceRole=primary,cnpg.io/podRole=instance,role=primary
Au niveau de l’objet Service postgresql-rw, on peut facilement voir avec quel(s)
Pod(s) il s’associe en consultant la valeur de la propriété Selector :
kubectl describe service postgresql-rw | grep Selector
Selector: cnpg.io/cluster=postgresql,cnpg.io/instanceRole=primary
Le Service postgresql-rw sera associé aux Pods faisant partie du cluster
postgresql et ayant instanceRole positionné à primary. Ici il n’y en aura
évidemment qu’un seul, puisqu’il ne peut y avoir qu’un seul primaire sur
PostgreSQL.
Lors d’une bascule (qu’elle soit automatique ou déclenchée), les labels
sont mis à jour pour refléter la réalité. Les Services s’associent donc avec
les bons Pods selon le Selector qu’ils portent.
Testons cela avec la commande suivante. Elle utilise le plugin CloudNativePG
pour kubectl. Elle permet de promouvoir l’instance postgresql-1 comme nouveau primaire du cluster postgresql.
kubectl cnpg promote postgresql 1
La situation est donc désormais la suivante :
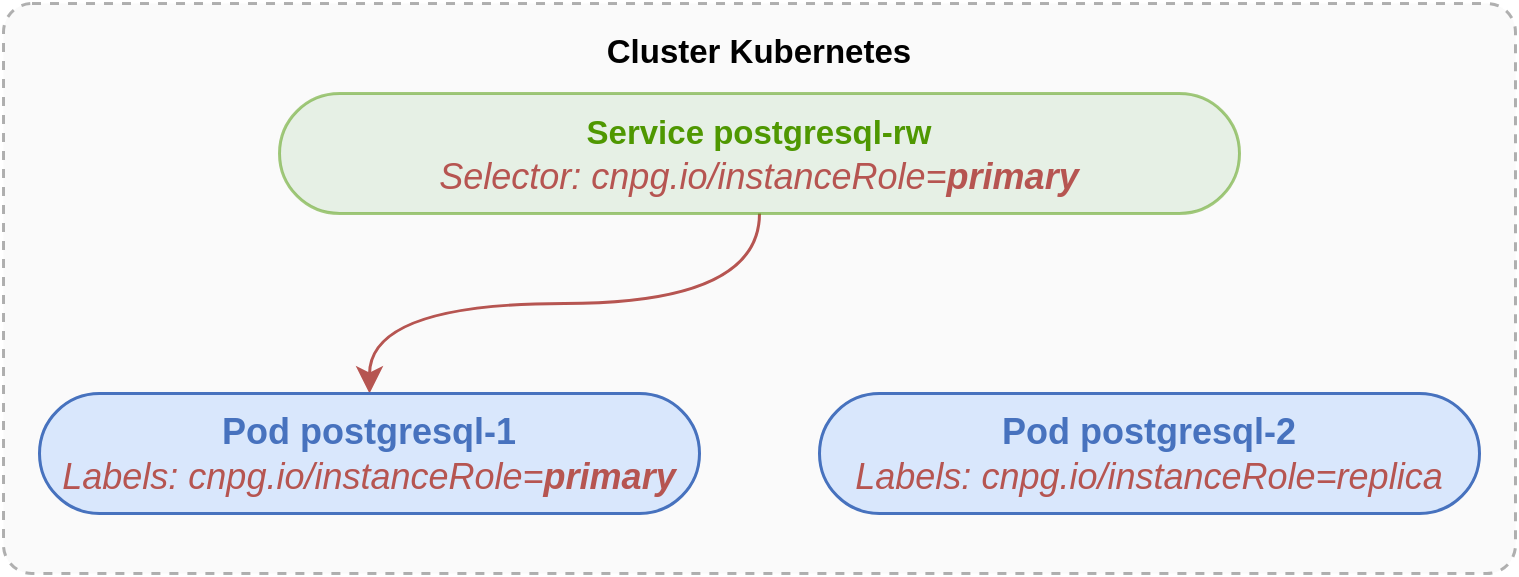
Lors de l’opération précédente, les labels ont bien été mis à jour. C’est ce qu’on peut voir avec la commande suivante.
kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
[...]
postgresql-1 1/1 Running 0 69m cnpg.io/cluster=postgresql,cnpg.io/instanceName=postgresql-1,cnpg.io/instanceRole=primary,cnpg.io/podRole=instance,role=primary
postgresql-2 1/1 Running 1 (2m32s ago) 85m cnpg.io/cluster=postgresql,cnpg.io/instanceName=postgresql-2,cnpg.io/instanceRole=replica,cnpg.io/podRole=instance,role=replica
Dans pgAdmin4, vous pouvez relancer une requête et voir que … 💥
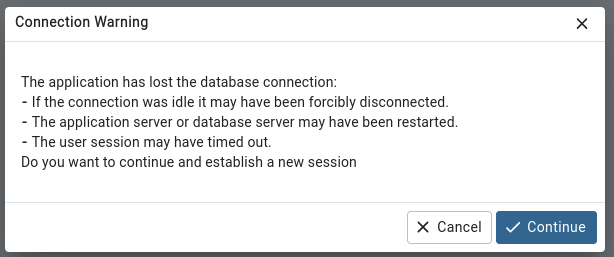
pgAdmin4 se rend compte que la connexion a été perdue. Rien de bien surprenant à
vrai dire. Lorsqu’une bascule a lieu, toutes les connexions sont fermées.
L’outil doit donc en ouvrir une nouvelle. En cliquant sur Continue une
nouvelle connexion sera effectuée et vous obtiendrez alors le résultat escompté.
Vous n’avez pas eu à modifier les informations de connexion. pgAdmin4 passe
toujours via le Service postgresql-rw.
Conclusion
CloudNativePG crée et gère un ensemble de ressources Kubernetes pour administrer
des instances PostgreSQL. Dans cet article, nous avons vu l’intérêt et
l’importance des Services, qui jouent un rôle clé dans les bascules
automatiques et dans la connectivité des applications à l’instance PostgreSQL.
Une bonne compréhension de leur fonction par les DBAs PostgreSQL est donc
essentielle.
Avec l’exemple de la promotion manuelle, vous avez un aperçu du changement qu’impliquera l’utilisation d’un opérateur dans le travail quotidien d’un administrateur PostgreSQL.
La suite dans le prochain épisode 🐘.
Des questions, des commentaires ? Écrivez-nous !