Paris, le 13 décembre 2024
Nous optimisons beaucoup de requêtes SQL pour nos clients. Certains de mes collègues ne sont d’ailleurs satisfaits que lorsque le temps d’exécution est réduit d’un facteur 100. Aujourd’hui, voyons comment, parfois, nous pouvons obtenir bien mieux, très facilement.

Le problème
Dans un ticket que nous avons reçu, la requête que nous avons eue à étudier avait la forme suivante :
SELECT column_a, created_at
FROM table_a
WHERE
external_id = (SELECT id FROM table_b WHERE unique_key = '_UNiquEv41ue_')
AND LOWER(column_b) = 'a2bc-34de-45f0'
AND some_id = -1234
AND other_id = (SELECT id FROM table_c WHERE some_id = table_a.some_id)
ORDER BY created_at DESC
LIMIT 1
Trois tables doivent être consultées, plusieurs filtres sont présents, ainsi
qu’un ORDER BY nécessitant un tri. Le plan d’exécution initial de cette
requête, récupéré avec la commande EXPLAIN (ANALYZE) montre une durée
d’exécution de 4 minutes (240000 ms) :
Limit
-> Sort
Sort Key: table_a.created_at DESC
Sort Method: top-N heapsort
InitPlan 1
-> Index Scan using unique_key_constraint on table_b
Index Cond: (unique_key = '_UNiquEv41ue_')
-> Bitmap Heap Scan on table_a
Recheck Cond: (external_id = $0 AND some_id = '-1234')
Rows Removed by Index Recheck: 10807340
Filter: (lower(column_b) = 'a2bc-34de-45f0' AND other_id = SubPlan 2)
-> Bitmap Index Scan on idx_pas_tout_a_fait_adapte
Index Cond: (external_id = $0 AND some_id = '-1234')
SubPlan 2
-> Seq Scan on table_c
Filter: (some_id = table_a.some_id)
Rows Removed by Filter: 5
Planning time: 18.432 ms
Execution time: 240021.889 ms
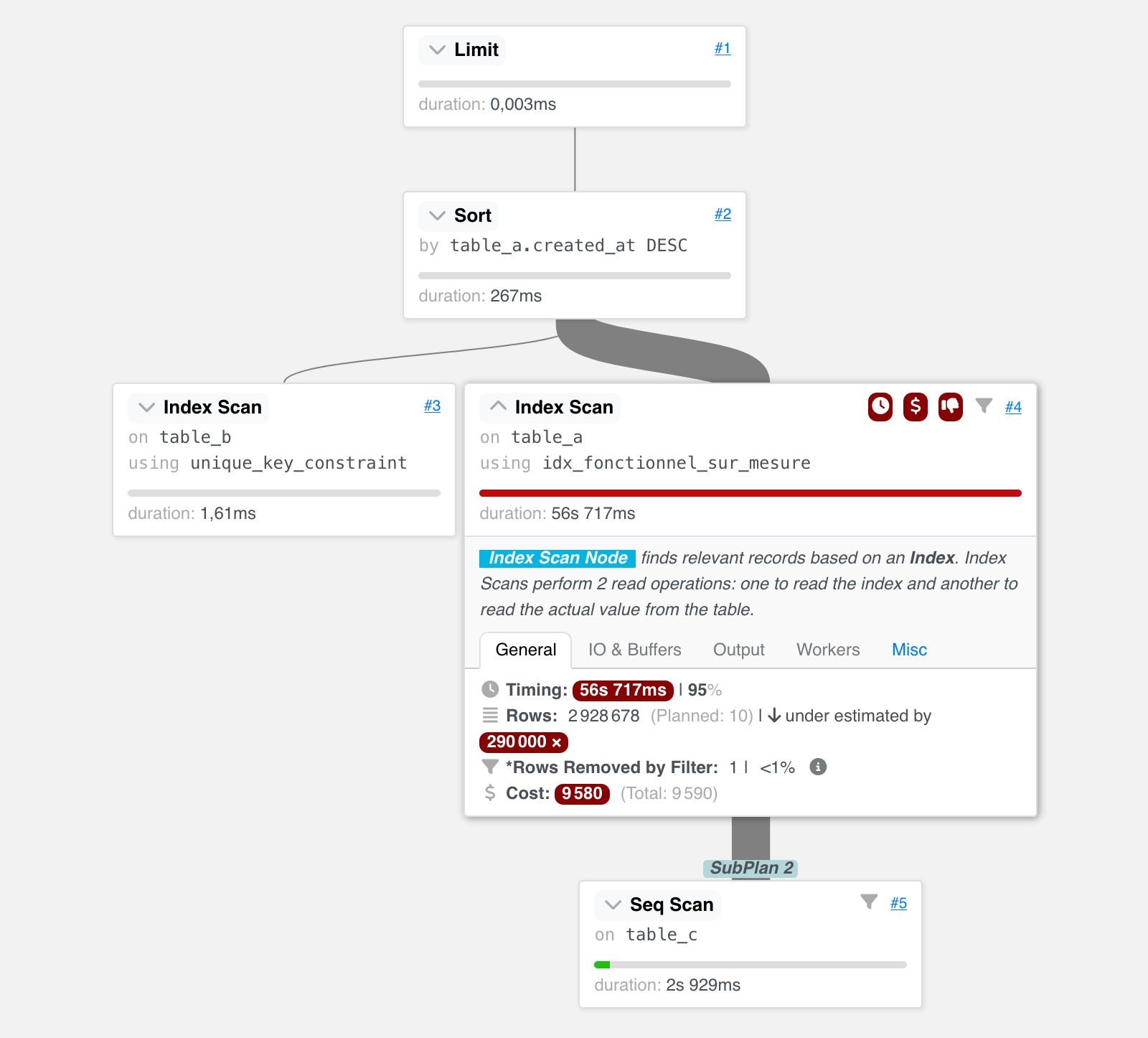
Pour davantage de lisibilité, le plan ci-dessus a été simplifié, vous pouvez retrouver le plan texte complet et sa représentation graphique interactive sur explain.dalibo.com. Cet outil nous permet de grandement faciliter l’analyse, voici une capture d’écran :

Nous remarquons que le parcours d’index sur la table_a a posé
problème, l’index utilisé n’est pas optimal pour cette requête.
Création d’un index fonctionnel
Un bon réflexe dans cette situation est souvent de créer un index adapté à la
requête à optimiser. Avant de nous consulter, notre client a donc
testé un index fonctionnel sur LOWER(column_b) et d’autres
colonnes :
CREATE INDEX idx_fonctionnel_sur_mesure ON table_a(external_id, LOWER(column_b), some_id);
La création d’un index comme celui-ci n’est pas neutre : sa construction sur trois colonnes, et sa taille importante, rendent son utilisation par d’autres requêtes moins probable. L’utilité de l’index est à mettre en regard de son coût de maintenance (écritures supplémentaires à chaque mise à jour de la table).
Cette approche a permis de diviser par 4 le temps d’exécution de la requête. C’est une belle amélioration, mais la requête dure encore une minute, avec le plan suivant, qui utilise bien l’index nouvellement créé :
Limit
-> Sort
Sort Key: table_a.created_at DESC
Sort Method: top-N heapsort
InitPlan 1
-> Index Scan using unique_key_constraint on table_b
Index Cond: (unique_key = '_UNiquEv41ue_')
-> Index Scan using idx_fonctionnel_sur_mesure on table_a
Index Cond: (external_id = $0 AND lower(column_b) = 'a2bc-34de-45f0' AND some_id = '-1234')
Filter: (other_id = SubPlan 2)
Rows Removed by Filter: 1
SubPlan 2
-> Seq Scan on table_c
Filter: (some_id = table_a.some_id)
Rows Removed by Filter: 5
Planning time: 0.702 ms
Execution time: 59914.876 ms
En consultant le nouveau plan, nous
constatons que l’accès à table_a a basculé d’un Bitmap Scan à un
Index Scan. Ce dernier est plus efficace, en partie car il n’a pas besoin de
revérifier chaque ligne trouvée (Recheck). (Le nœud Bitmap Heap Scan
revérifie toutes les lignes des blocs que le Bitmap Index Scan trouve, car le
work_mem est insuffisant pour être plus précis).
Ce nouveau plan reste encore trop long :
Les statistiques à la rescousse !
En effet, il est clair que l’estimation du nombre de lignes filtrées par les différentes conditions ne sont pas bonnes. Dans ce cas, la première chose à faire est de mettre à jour les statistiques sur la table :
ANALYZE table_a;
Nous avons demandé à notre client de passer ensuite de nouveau la requête avec
EXPLAIN (ANALYZE) et deux choses intéressantes sont apparues
(représentation graphique) :
Limit
-> Index Scan Backward using idx_tc on table_a
Filter: (external_id = $0 AND some_id = '-1234' AND lower(column_b) = 'a2bc-34de-45f0' AND other_id = SubPlan 2)
Rows Removed by Filter: 7
InitPlan 1
-> Index Scan using unique_key_constraint on table_b
Index Cond: (unique_key = '_UNiquEv41ue_')
SubPlan 2
-> Seq Scan on table_c
Filter: (some_id = table_a.some_id)
Rows Removed by Filter: 5
Planning time: 25.429 ms
Execution time: 4.527 ms
L’optimiseur a fait le choix intéressant d’un parcours d’index inversé très
adapté à la condition ORDER BY DESC. Malgré un coût relatif encore important,
le temps d’exécution de ce nœud est désormais extrêmement rapide, à quelques
millisecondes.
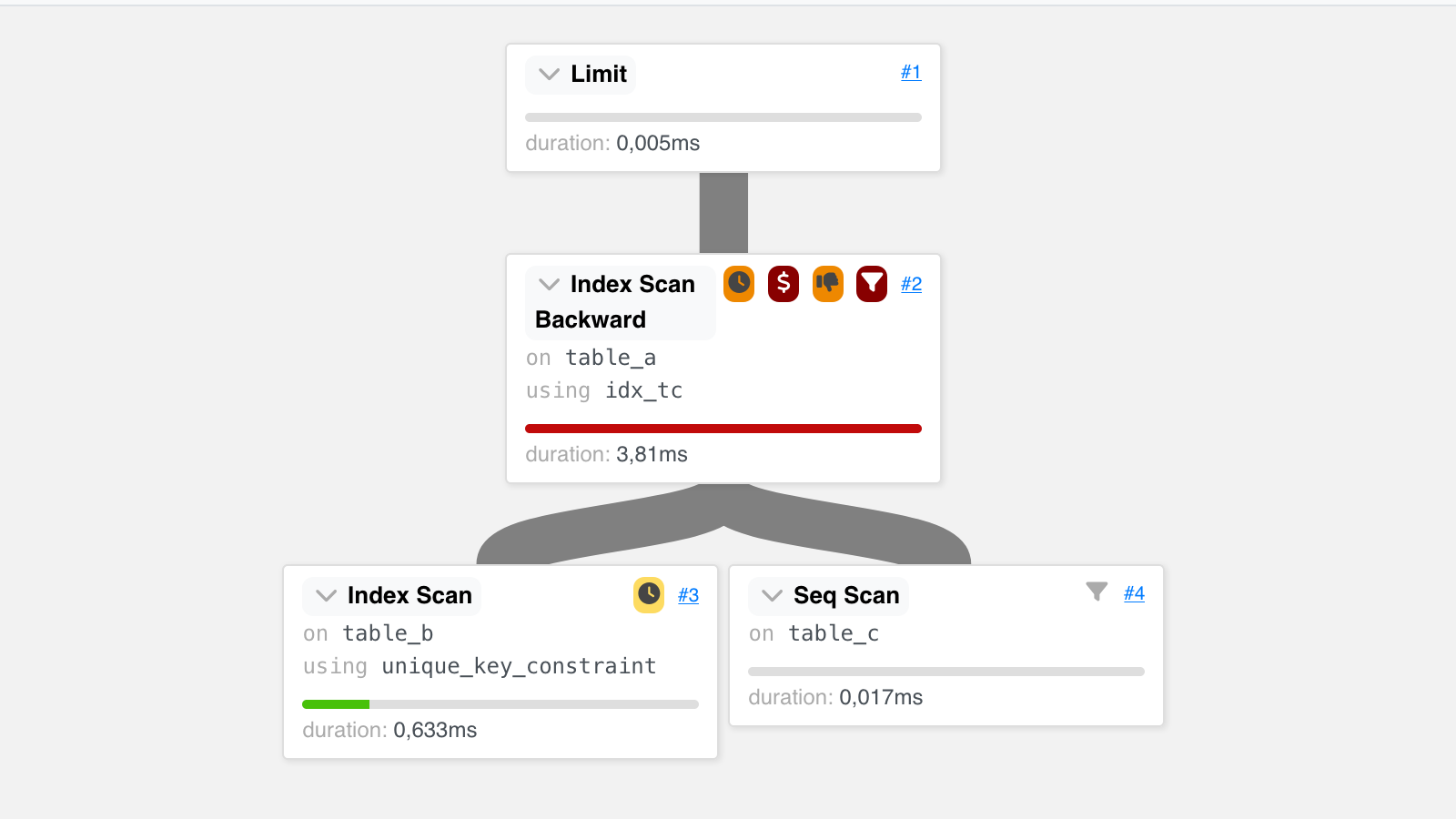
La planification et l’exécution de la requête ne prennent plus que 30 ms ! Nous remarquons aussi que l’index créé précédemment n’est plus utilisé. On pourra le supprimer pour éviter des écritures inutiles. La simple mise à jour des statistiques nous permet d’obtenir une exécution 10 000 fois plus rapide, sans avoir besoin de créer de nouvel index, coûteux en maintenance.
L’icône au pouce baissé dans la visualisation sur
explain.dalibo.com indiquait une grosse
sous-estimation dès le plan original. Dans cette situation, ANALYZE doit être
le premier réflexe avant d’étudier un nouvel index ou une réécriture de la
requête. La vraie question était donc : pourquoi les statistiques
n’étaient-elles pas à jour ? Le processus autovacuum se charge normalement de
les recalculer régulièrement, et son paramétrage devra être vérifié.
Pour plus de détails concernant la mise à jour des statistiques avec ANALYZE,
vous pouvez vous référer à nos manuels de formation DBA1
et PERF1.