Lyon, le 14 juin 2024
Notre série d’articles concernant le moteur PostgreSQL continue. Au programme aujourd’hui : les journaux de transactions. Éléments incontournables de PostgreSQL, les journaux de transactions (ou fichiers WAL) sont essentiels au bon fonctionnement d’une instance mais sont également au cœur du mécanisme de sauvegarde PITR (Point In Time Recovery) et de réplication. Mais que contiennent-ils exactement ?

Plongeons dans les entrailles des journaux de transactions avec pg_waldump !
Quésaco ?
Le mécanisme de Write-Ahead Logging (ou WAL) est implémenté dans le moteur de PostgreSQL. Le principe est assez simple : il s’agit de consigner l’ensemble des modifications effectuées sur les données dans une série de journaux de transactions, les WAL. Chaque écriture est donc réalisée en mémoire, puis consignée dans ces journaux. PostgreSQL les applique dans les fichiers de données en tâche de fond, en lot et de manière régulière. Aussi, dans l’éventualité d’un crash où le contenu de la mémoire est alors perdu, il est possible de lire ces journaux pour rejouer les opérations et revenir à un état cohérent de l’instance.
Belle présentation, n’est-ce pas ? Mais concrètement, qu’est-ce que c’est qu’un WAL ?
Commençons par ce qui est le plus simple. Un fichier WAL est un segment de 16 Mo
et se trouve par défaut dans le dossier pg_wal du $PGDATA. Il est composé de
24 caractères.
ls -lh /var/lib/pgsql/16/data/pg_wal/
total 17M
-rw------- 1 postgres postgres 16M May 17 07:40 000000010000000000000001
drwx------ 2 postgres postgres 4.0K May 17 07:36 archive_status
Le nom d’un segment comporte son numéro de timeline, le numéro du WAL de 4 Go dont il fait partie et son numéro propre, le tout en hexadécimal. Si nous prenons par exemple le premier fichier ci-dessus, nous trouvons :
00000001: qui correspond à la timeline1;00000000: qui correspond au journal0de 4 Go ;00000001: qui correspond au segment1du journal0, de 16 Mo.
Il est possible de retrouver les informations du fichier WAL en cours
d’utilisation grâce aux fonctions pg_current_wal_lsn() et pg_walfile_name().
postgres=# select pg_current_wal_lsn();
pg_current_wal_lsn
--------------------
0/19D6FD8
(1 row)
postgres=# select pg_walfile_name('0/19D6FD8');
pg_walfile_name
--------------------------
000000010000000000000001
(1 row)
Le résultat de la première fonction peut se lire de la manière suivante :
0: est le numéro du WAL de 4 Go ;/1: est le numéro de segment (0x19D6FD8 / 0x1000000) ;9D6FD8: est l’emplacement de la prochaine écriture dans le segment (0x19D6FD8 % 0x1000000).
Comme expliqué un peu plus haut, les écritures sont faites de manière séquentielle dans les fichiers WAL. Il est donc nécessaire de connaître l’emplacement de la prochaine insertion dans le fichier WAL.
Analyse avec l’outil pg_waldump
Insérons une nouvelle ligne dans une table déjà existante et ne contenant
qu’une colonne de type entier : insert into t1 values (1). L’outil pg_waldump
va nous permettre de comprendre un peu plus ce qu’il se passe avec les WALs. Il
s’utilise de la manière suivante, où 000000010000000000000001 est le nom du
fichier WAL courant et -f l’option qui permet de suivre en temps réel les
modifications.
/usr/pgsql-16/bin/pg_waldump -f $PGDATA/pg_wal/000000010000000000000001
# insert into t1 values (1);
rmgr: Heap len (rec/tot): 54/ 186, tx: 745, lsn: 0/019D7010, prev 0/019D6FD8, desc: INSERT off: 3, flags: 0x00, blkref #0: rel 1663/16384/16385 blk 0 FPW
rmgr: Transaction len (rec/tot): 34/ 34, tx: 745, lsn: 0/019D70D0, prev 0/019D7010, desc: COMMIT 2024-05-17 07:44:16.298141 UTC
Regardons la première ligne du WAL après l’insertion. Plusieurs éléments sont intéressants :
745est l’identifiant de la transaction qui a effectué l’INSERT;lsnsignifie Log Segment Number. La valeur correspond bien à ce qui avait été donné parpg_current_wal_lsn(). Il est suivi par le précédantlsn(prev) ;descindique l’opération exécutée ;off(pouroffset) détermine l’emplacement de l’écriture dans le bloc de donnée ;- enfin, le champ
rel 1663/16384/16385est très intéressant car il indique concrètement quel fichier est concerné par cette modification.
Sur les autres lignes d’autres éléments peuvent être notés, comme par exemple
l’horodatage du COMMIT : COMMIT 2024-05-17 07:44:16.298141 UTC.
Nous avons retrouvé l’identifiant de transaction grâce à pg_waldump. Cette
valeur se retrouve également dans la colonne xmin de la table en question. La
colonne xmin, comme xmax, est cachée par défaut, mais vous pouvez les
retrouver en les mentionnant explicitement.
d1=# select xmin, xmax, i from t1;
xmin | xmax | i
------+------+---
745 | 0 | 1
Elle correspond à l’identifiant de la transaction qui a créé cette version de la ligne. Si vous souhaitez en savoir plus sur cette mécanique de version de ligne et de snapshot, allez jeter un œil sur notre module de formation juste ici.
Ces journaux contiennent donc toutes les modifications, survenant dans tous les fichiers de données et à quels emplacements. Pour reconstruire une instance, il suffit de demander à PostgreSQL d’appliquer les enregistrements contenus dans les journaux.
Influence du paramètre wal_level
Selon les besoins (réplication logique, sauvegarde PITR), il est nécessaire de
modifier la quantité d’informations présentes dans ces fichiers WAL. Cette
configuration se fait grâce au paramètre wal_level. Il peut prendre trois
valeurs : minimal, replica ou logical. Par défaut, ce paramètre est
configuré à replica, ce qui est adapté pour la mise en place d’une réplication
physique, ou d’une sauvegarde PITR.
Lorsque ce paramètre est positionné à logical, la quantité de données écrites dans
les WAL est nettement supérieure. C’est l’objet de notre test de benchmark.
Benchmark
Encore une fois, l’outil pgbench est utilisé pour effectuer ce test.
L’idée est d’effectuer le même test de charge une première fois avec le
paramètre wal_level positionné à minimal, puis à replica et enfin à
logical, puis de comparer la volumétrie de WAL générée dans chacun des cas.
La base de données utilisée fait environ 50 Go et a été initialisée grâce à la
commande pgbench suivante :
pgbench -i -s 3400
Le test s’est déroulé sur des périodes de 5 minutes (option --time de la
commande) et avec la simulation de 10 clients (option --client).
pgbench --time 300 --client 10
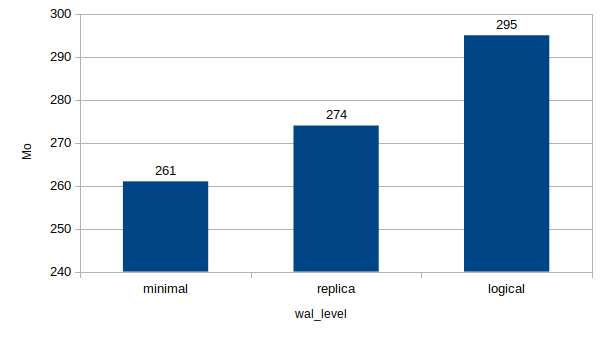
Les résultats de nos tests sont les suivants. Une augmentation de 4.5% d’espace
disque est à noter entre la configuration minimal et replica. Une
augmentation d’environ 7.5% est à relever entre le mode replica et logical.
Conclusion
La configuration du paramètre wal_level est incontournable lors de
l’installation de votre instance. Choisissez le paramètre qui vous convient selon
vos besoins. Ne le positionnez pas à logical si votre seul besoin est de
pouvoir retrouver votre instance après un crash (recovery), minimal suffira
dans ce cas là.
Un certain adage dit que “Qui peut le plus, peut le moins !” … certes,
mais à quel prix ? Des écarts importants existent entre la volumétrie de WAL
générée selon le paramétrage de wal_level.
Cet article, un peu moins technique que les précédents, fait office d’une belle piqûre de rappel sur ce qu’est un journal de transactions et de son utilité. Savez-vous que les journaux de transactions sont intimement liés aux checkpoints ? Notre premier article donne quelques détails là dessus. N’hésitez à aller le (re)lire.
Des questions, des commentaires ? Écrivez-nous !
- PostgreSQL (476) ,
- Dalibo (199) ,
- 2024 (6) ,
- mainsdanslecambouis (5) ,
- wal (1) ,
- journaux (1) ,
- transaction (5) ,
- planetpgfr (50)