Lyon, le 5 janvier 2024
Voici le premier numéro d’une série d’articles concernant le fonctionnement de PostgreSQL. Nommée « Les mains dans le cambouis », elle consistera, comme son titre le laisse suggérer, à détailler et comprendre le fonctionnement du moteur de PostgreSQL.

Et pour ce premier article, nous avons choisi de parler du sujet des checkpoints, de leur utilité, de leur lien avec le cache et des paramètres qui existent pour les configurer.
Quésaco ?
Un petit tour sur la documentation de PostgreSQL nous permet de trouver la bonne définition d’un checkpoint (voir wal-configuration). Il s’agit d’un instant précis, dans la timeline d’une instance, à partir duquel on peut considérer que les fichiers sur disque sont bien à jour avec ce qui a été enregistré dans les journaux de transactions jusqu’au début de l’exécution du checkpoint.
C’est le processus checkpointer de l’instance qui se charge de cela en
déclenchant aussi souvent que possible des checkpoints. Il existe également la
commande SQL CHECKPOINT qui permet d’en déclencher manuellement. D’autres activités de l’instance déclenchent aussi des checkpoints automatiques, comme l’arrêt de l’instance, une sauvegarde PITR, etc.
Rappelons que, dans son fonctionnement normal, PostgreSQL n’écrit pas directement sur disque dans les fichiers de données, mais le fait dans des journaux de transaction. Les fichiers de données sont modifiés dans le cache, donc en mémoire. C’est le processus checkpointer qui va régulièrement les écrire sur disque pour nettoyer le cache.
Cache partagé
Pour comprendre ce qu’il se cache derrière “nettoyer le cache”, il est
nécessaire de se pencher sur le cache de PostgreSQL. La taille de ce dernier est configurée
grâce au paramètre shared_buffers, positionné par défaut à 128 Mo.
PostgreSQL travaille avec des blocs de 8 ko, cela revient donc à 16384 blocs de
données alloués au cache partagé.
Le module pg_buffercache
permet d’examiner son contenu et son état.
Cette extension fournit la vue pg_buffercache qui permet de voir facilement
le contenu du cache en retournant une ligne par bloc. Pour chaque bloc de 8 ko,
les informations dont on dispose sont les suivantes :
demo=# \x
Expanded display is on.
demo=# select * from pg_buffercache ;
-[ RECORD 1 ]----+------
bufferid | 1 -- ID du bloc
relfilenode | 1262 -- numéro du fichier sur disque
reltablespace | 1664 -- OID du tablespace où se trouve la relation
reldatabase | 0 -- OID de la base de données où se trouve la relation
relforknumber | 0 -- numéro du fork dans la relation
relblocknumber | 0 -- numéro du bloc de la relation
isdirty | f -- est ce que le bloc est modifié (dirty dans la VO)
usagecount | 5 -- compteur lié au clock-sweep
pinning_backends | 0 -- nombre de processus utilisant ce bloc
Plusieurs éléments sont intéressants dans ces informations, mais limitons-nous
pour le moment à isdirty. Il indique si le bloc en question a été écrit sur
disque (false) ou si sa version modifiée n’est présente que dans le cache (true). Les blocs
dirty verront leur contenu être écrit sur disque lors du prochain passage d’un
checkpoint.
Partons d’une instance tout juste installée et créons une nouvelle base demo.
postgres=# create database demo;
CREATE DATABASE
postgres=# \c demo
You are now connected to database "demo" as user "postgres".
demo=# create extension pg_buffercache ;
CREATE EXTENSION
Créons une nouvelle table t1.
demo=# create table t1 (i integer);
CREATE TABLE
L’extension pg_buffercache permet de remonter
que 16 blocs du cache ont été modifiés.
demo=# select count(*) from pg_buffercache where isdirty;
count
-------
16
(1 row)
En effet, la création d’une table va écrire des données dans différents catalogues systèmes (pg_class, pg_attribute pour ne citer que les deux plus évidents). Ces 16 blocs concernent donc les catalogues systèmes. Si nous forçons le passage d’un checkpoint, ces blocs-là seront écrits sur disque.
demo=# CHECKPOINT;
CHECKPOINT
demo=# select count(*) from pg_buffercache where isdirty;
count
-------
0
(1 row)
Dès lors qu’une opération est faite sur la table, par exemple une insertion,
PostgreSQL aura besoin de blocs du cache, qui seront alors considérés comme dirty.
Insérons plusieurs entiers dans la table t1 :
demo=# insert into t1 select generate_series(1,10000);
INSERT 0 10000
demo=# select count(*) from pg_buffercache where isdirty;
count
-------
49
(1 row)
49 blocs du cache ont été utilisés pour l’opération d’INSERT. Ils sont donc
marqués comme dirty. CHECKPOINT permet de nettoyer le cache. Plus aucun bloc
n’est considéré dirty.
demo=# CHECKPOINT;
CHECKPOINT
demo=# select count(*) from pg_buffercache where isdirty;
count
-------
0
(1 row)
“Plus aucun bloc n’est considéré dirty“, cela ne signifie pas que les blocs ont
disparu du cache. Bien au contraire, ils restent là tant que PostgreSQL estime
en avoir besoin. La partie Notions essentielles de gestion du cache de notre formation
DBA2
décrit les notions et mécanismes à ce sujet.
demo=# SELECT
relname,
isdirty,
count(bufferid) AS blocs,
pg_size_pretty(count(bufferid) * current_setting ('block_size')::int) AS taille
FROM pg_buffercache b
INNER JOIN pg_class c ON c.relfilenode = b.relfilenode
WHERE relname = 't1'
GROUP BY relname, isdirty;
relname | isdirty | blocs | taille
---------+---------+-------+--------
t1 | f | 49 | 392 kB
(1 row)
Les traces de l’instance montrent en détail ce qu’il s’est passé lors du
checkpoint. Le paramètre log_checkpoints doit être configuré à on.
2023-12-27 16:18:49.315 CET [68301] LOG: checkpoint starting: immediate force wait
2023-12-27 16:18:49.327 CET [68301] LOG: checkpoint complete: wrote 50 buffers (0.3%); 0 WAL file(s) added, 0 removed, 0 recycled; write=0.003 s, sync=0.003 s, total=0.013 s; sync files=4, longest=0.002 s, average=0.001 s; distance=630 kB, estimate=1853 kB; lsn=0/1B971D0, redo lsn=0/1B97198
checkpoint starting: immediate force waitindique que le checkpoint a été démarré car forcé manuellement ;checkpoint completeindique que l’opération s’est bien terminée et donne des détails supplémentaires, notamment :wrote 50 buffers (0.3%)qui indique le nombre de buffers écrits et indique également qu’ils correspondent à 0,3% du cache partagé de l’instance ;lsn=0/1AF3E48qui indique le Log Segment Number lors de la fin du checkpoint ;- et
redo lsn=0/1AF3E10qui indique le Log Segment Number au début du checkpoint. C’est à partir de cet instant là qu’il faudra rejouer les journaux de transactions.
En plus de faire le ménage dans le cache partagé (suppression du flag dirty)
et d’écrire dans les fichiers de données, un checkpoint va également
ajouter un enregistrement checkpoint dans les journaux de transactions et sa position dans
le fichier global/pg_control de l’instance.
L’utilitaire pg_controldata permet de retrouver ces informations là sans
devoir lire le fichier de traces :
$ pg_controldata . | grep -E "(Latest checkpoint location)|(Latest checkpoint's REDO)"
Latest checkpoint location: 0/1B971D0
Latest checkpoint's REDO location: 0/1B97198
Latest checkpoint's REDO WAL file: 000000010000000000000001
La troisième ligne indique quel journal de transactions est associé au
redo lsn. Tous les journaux antérieurs à celui-ci ne sont donc désormais plus
utiles et pourront être recyclés automatiquement par PostgreSQL.
Paramétrage des checkpoints
Nous avons vu en quoi consiste une opération de checkpoint et en avons lancé manuellement. Comme dit précédement, un processus serveur (checkpointer) est dédié à l’exécution de cette opération. Il s’agit en fait d’une boucle d’exécution qui va s’exécuter puis dormir pendant un certain temps et pourra être interrompue à la réception de certains signaux.
Plusieurs paramètres influencent le comportement du checkpointer.
Tout d’abord, le paramètre checkpoint_timeout indique le temps maximal entre
deux checkpoints. Par défaut, il est configuré à 5 minutes. Nous verrons plus
tard que réduire au minimum cette durée n’est pas une bonne idée mais que l’augmenter pourrait être intéressant.
PostgreSQL calcule le temps passé entre les deux derniers checkpoints
et applique la valeur du paramètre checkpoint_completion_target (0,9 par
défaut). La durée obtenue indique le temps que doit passer le checkpointer à
écrire sur disque les blocs du cache considérés comme dirty. L’idée est de
lisser au mieux les écritures sur disque pour permettre aux autres processus
d’accéder plus rapidement aux disques.
max_wal_size indique la taille maximale d’écriture dans les journaux de
transactions entre deux checkpoints. Si elle est dépassée avant l’expiration
du délai checkpoint_timeout, un checkpoint
est déclenché. De ce fait, un checkpoint peut être déclenché de deux
manières :
- par expiration du temps (
time) ; - ou par dépassement de cette volumétrie (
wal).
Lien entre les checkpoints et la taille de pg_wal
Nous avons vu qu’un passage de checkpoint permet de savoir quels journaux de transaction ne sont plus utiles. Intuitivement, on comprend donc que plus les checkpoints sont éloignés, plus on conservera de journaux. Cette conclusion a une importance en cas de restauration de l’instance. En effet, le temps de restauration sera d’autant plus rallongé que le nombre de journaux est important.
On aurait donc envie de réduire au minimum le paramètre checkpoint_timeout
pour accélérer la reprise. Oui, mais … non. Ce n’est pas une si bonne idée que
cela.
Dans le cas où le paramètre full_page_writes est configuré à on (ce qui est par
défaut le cas et ne doit être changé que pour des cas très précis en connaissance de cause),
il reste un autre facteur à considérer. Ce paramètre force
PostgreSQL à écrire intégralement, dans le journal de transaction en cours, le
bloc complet lors de sa première modification après un checkpoint. Ceci afin de s’assurer
que ce bloc puisse être entièrement restauré en cas de crash. Une explication
plus détaillée se trouve sur la page
wiki du projet PostgreSQL.
Dans ce cas-là donc, un intervalle de checkpoints plus petit augmentera le volume d’écriture des journaux de transaction, annulant en partie l’intérêt d’utiliser cet intervalle plus petit et générant plus de sollications disques.
Pour illustrer nos propos, voici les résultats d’un test montrant le lien entre
le paramètre checkpoint_timeout (abscisses) et la volumétrie de journaux
générés (ordonnées). Chaque test individuel a duré environ une heure, le test global a donc pris 5 heures. L’outil utilisé pour générer de l’activité est pg_bench.
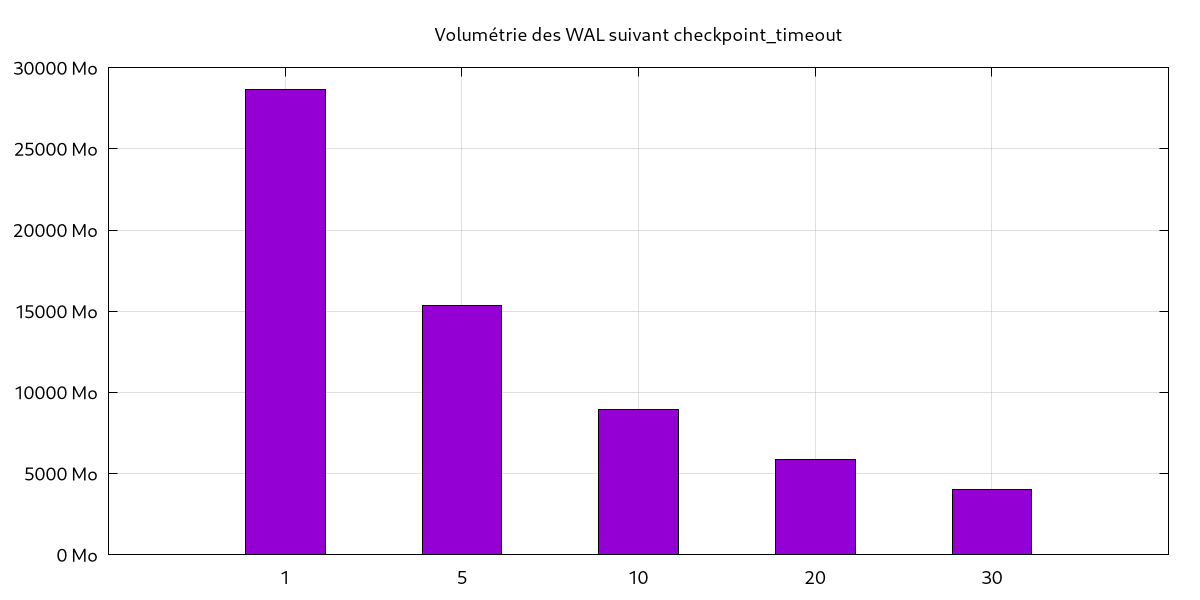
Ce qui a été dit juste avant se vérifie parfaitement avec ce graphique : avec un
checkpoint_timeout à 1min, le volume de journaux atteint presque 30 Go
tandis qu’avec 30min, la volumétrie est inférieure à 5 Go. La différence est
très marquée et mérite d’être signalée : moins d’écritures disques, moins de journaux
à archiver pour les sauvegardes PITR, moins de données à envoyer (en flux ou par
segment) aux serveurs secondaires dans le cas d’une réplication. Les avantages sont
conséquents, et les inconvénients mineurs. Si l’instance PostgreSQL se trouve
installée sur un serveur avec des capacités de stockage réduites, il pourrait
être intéressant d’utiliser un checkpoint_timeout élevé (dans ce cas-là, ne pas
oublier de faire suivre max_wal_size). Pour autant, les journaux de
transactions seront conservés plus longtemps et le temps de reprise en cas de
crash sera également allongé.
Comme souvent avec PostgreSQL, il faut faire preuve d’équilibre pour trouver la configuration qui convient le plus à la charge de travail.
Conclusion
Et voilà, c’est la fin de notre premier article Les mains dans le cambouis sur les checkpoints. Nous venons de découvrir une (petite) partie du moteur PostgreSQL. Les checkpoints sont essentiels au bon fonctionnement de l’instance et méritent d’être compris et configurés correctement. Le prochain sujet technique n’est pas encore déterminé.
Des questions, des commentaires ? Écrivez-nous !
- PostgreSQL (480) ,
- Dalibo (200) ,
- mainsdanslecambouis (5) ,
- 2024 (6) ,
- checkpoints (1) ,
- planetpgfr (53)