Paris, le 2 avril 2020
En mai 2019, comme tous les ans, à Ottawa, plusieurs centaines de passionnés sont venus pour assister à la conférence la plus importante du monde PostgreSQL : la PGCon.
Sur 4 jours se sont succédées des sessions de travaux pratiques aka Tutorials, des rencontres entre les développeurs principaux aka Developer Meeting et Unconference, et pas loin de 35 conférences.
Dans 2 mois, du 26 au 29 mai, aura lieu la quatorzième itération de cet évènement. Particularité de cette année, à cause de la pandémie au COVID-19, cette conférence se tiendra en ligne. Plus d’informations sur l’organisation seront fournies dans les semaines à venir. En attendant, retour sur quelques discussions importantes de l’année dernière.

Les conférences
Les sujets abordés durant les conférences du PGCon sont très divers, et souvent
aussi très pointus.
Les nouvelles fonctionnalités de la version majeure de l’année sont
décortiquées. Les axes de développement pour les futures versions sont
débattus.
En 2019, deux sujets ont particulièrement retenu notre attention :
Direct and Asynchronous I/O- les
Pluggable Table Storage
Nous évoquerons le premier point dans cet article. Nous reviendrons dans un second temps sur les nouvelles méthodes de stockage des données.
Direct and Asynchronous I/O
Il est apparu en 2018 que le noyau Linux ne se comportait pas comme on s’y
attendait : le
fsyncgate.
On pouvait tomber sur des cas d’erreurs d’écriture non remontées à
PostgreSQL. Ce problème a été mitigé dans les versions suivantes des noyaux
Linux et PostgreSQL, mais une correction complète n’est pas possible sans
changer le mode actuel d’écriture sur disque, le buffered I/O.
D’autres modes d’écritures existent qui pourraient corriger le problème, comme le
Direct I/O. Des modes asynchrones pourraient améliorer certains traitements.
Ce sujet a été débattu lors d’une session des
unconference.
Tout d’abord, présentons ces différents modes d’écritures. Pour accéder à des
données stockées sur disque, tout processus passe par des opérations de
lectures et d’écritures. En Linux, un disque est représenté par un fichier de
périphérique stocké dans
le répertoire /dev (pour device). Il existe des latences lorsqu’une
opération est réalisée sur un disque. De plus, la taille minimale d’un bloc en
lecture et en écriture peut rendre les opérations peu performantes si elles
sont réalisées trop rapidement. On a tout intérêt à grouper les opérations pour
les rendre plus efficaces.
Mode buffered I/O
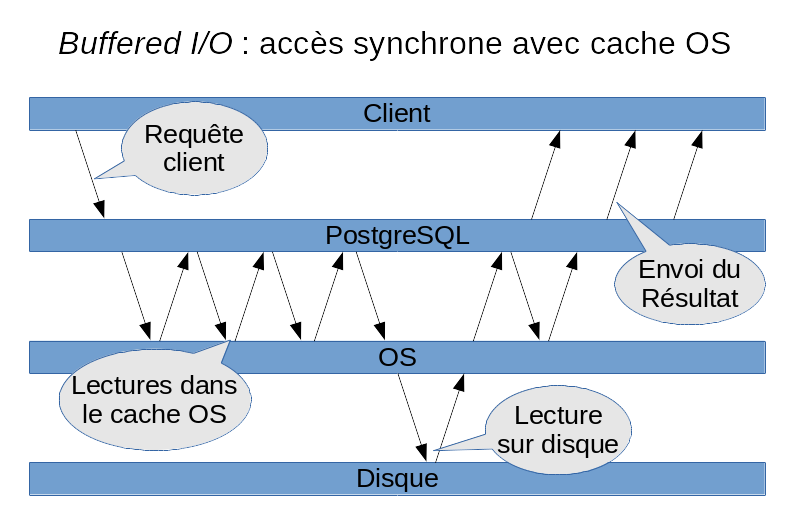
Dans le mode buffered I/O de PostgreSQL, nous allons confier le soin de gérer
les opérations de lectures / écritures au système d’exploitation (OS) et au
système de fichier (FS). À ce niveau, des tampons sont utilisés pour
optimiser les accès. Les données nécessaires au traitement d’une requête
peuvent être disponibles dans la mémoire partagée de PostgreSQL, les
shared_buffers, dans la négative, PostgreSQL les demande à l’OS.
En écriture, les changements sont stockés dans un espace mémoire
transitoire. Le système attend que l’écriture d’un certain volume de données
soit demandé pour déclencher l’écriture effective sur le disque. On peut forcer
la synchronisation sur disque des données présentes dans les tampons d’écriture
avant que l’OS l’ait décidé. On ne pourra cependant pas filtrer entre les
données écrites par notre processus et les données écrites par d’autres.
En lecture, le système récupère un certain volume de données et transmet des
parties de celui-ci au fur et à mesure au processus. Il conserve un certain
nombre de ses données en mémoire qu’il pourra fournir de nouveau à un processus
de façon rapide (un cache).
Certains accès sont réalisés de façon synchrone, le processus est alors bloqué
le temps que l’opération soit réalisée. PostgreSQL rencontre ces latences lors
des lectures et lors des synchronisations sur disque.
L’implémentation et les algorithmes d’accès disques de l’OS ont un coût. Ils sont en revanche optimisés et sûrs. Ils permettent de soulager le logiciel de nombreuses problématiques.
Mode Direct I/O
Le mode Direct I/O (DIO) permet de ne pas utiliser le système de cache de
l’OS. Le processus est alors seul responsable de l’accès au disque. Il doit
gérer les erreurs, les accès concurrents, le cache et la performance globale
des opérations. Il n’y a cependant pas de système de double stockage (OS et
processus) et on maîtrise le rythme des écritures. On gagne en performance côté
CPU et mémoire.
Le mode direct est déjà utilisé par PostgreSQL pour l’écriture des fichiers WAL
ainsi que pour quelques petits fichiers critiques (clog par exemple).
Au-delà des problèmes liés au fsyncgate, le fonctionnement actuel est
avantageux lorsque plusieurs instances sont installées sur un même serveur. Le
partage des ressources en lecture est bien géré.
Il existe de nombreux points pour lesquels le DIO permettrait des gains de
performance :
- Lorsqu’il y a de grandes quantités de données dans le cache au niveau
OS/FS, les phénomènes de double écriture et la non-spécialisation des accès pour PostgreSQL vont créer un goulot d’étranglement. - Dans le cas des scans séquentiels, le
read aheadne se déclenche pas toujours ou n’est pas toujours efficace, car il est non parallélisé. - Dans l’implémentation actuelle, le
background writerest peu utile. Il consomme beaucoup de ressources pour vérifier et suivre les écritures. Il n’écrit jamais rien.
Le passage en Direct I/O pour les écritures permettra une meilleure gestion
des erreurs et assurera la correction du fsyncgate. Par son fonctionnement,
il apportera des gains immédiats de performances. Les opérations étant gérées en
direct, elles seront plus prévisibles et il sera plus facile de surveiller
leurs avancées. Le cache de PostgreSQL (les shared buffers) nécessitera
toutefois d’être adapté pour mieux gérer les évictions de blocs.
Lecture asynchrone
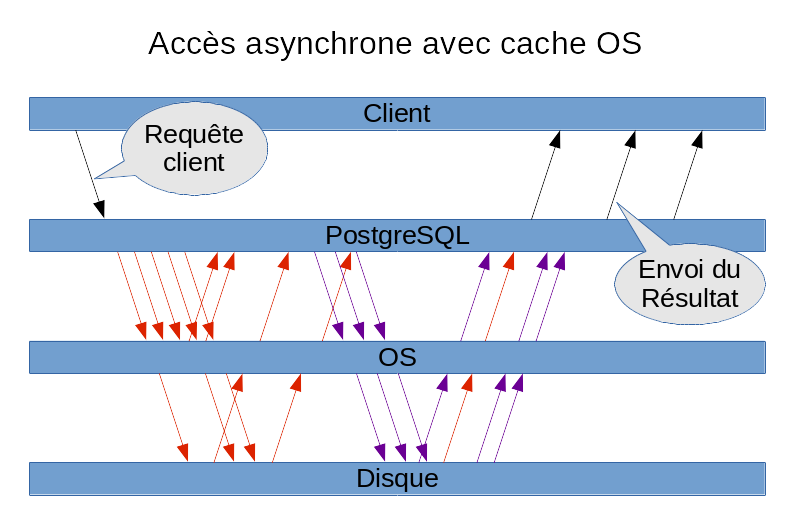
En mode asynchrone, un processus lance une opération, continue ses traitements et est notifié par le noyau lorsque l’opération est terminée. Ce mode pourrait permettre d’accélérer les scans séquentiels grâce à des lectures en avance mieux maîtrisées. Il pourrait également améliorer les écritures en les parallélisant.
Ces nouvelles fonctionnalités devront être configurables et désactivables. Il
n’est en effet pas garanti de les trouver sur tous les OS / FS.
Un point connexe est évoqué. Dans les blocs de données interne de PostgreSQL,
on stocke, en début de fichier, les pointeurs vers chaque ligne, et en fin de
fichier, mais dans l’ordre inverse, chaque ligne. Il n’y a pas de garantie sur
l’ordre des lectures en SQL. L’abandon de cette lecture dans l’ordre
d’insertion pourrait permettre des gains de performances.
Il faudra faire attention aux impacts et régressions possibles sur les requêtes
applicatives.
Andres Freund mène actuellement la réflexion sur ces sujets. La PGCon 2020 sera sûrement l’occasion de faire un point sur le sujet et de décider des changements d’implémentation à venir pour la version 14 de PostgreSQL.
À propos de la PGCon : PGCon est une conférence annuelle pour les utilisateurs et les développeurs de PostgreSQL, une base de données relationnelle de premier plan, qui se trouve être open source. PGCon est le lieu idéal pour se rencontrer, discuter, établir des relations, acquérir des informations précieuses et discuter du travail que vous faites avec PostgreSQL. Si vous voulez savoir pourquoi tant de gens se déplacent vers PostgreSQL, PGCon sera le lieu pour cela. Que vous soyez un utilisateur occasionnel ou que vous travailliez avec PostgreSQL depuis des années, PGCon aura quelque chose à vous offrir !
À propos de Dalibo : Depuis 2005, Dalibo est le spécialiste français de PostgreSQL et de ses logiciels satellites, qui met à la disposition de ses clients son savoir-faire dans le domaine des bases de données en offrant Support, Audits et conseils, Formations, Certification, et de nombreuses contributions à la communauté PostgreSQL.