Vauréal, le 4 décembre 2025
Cet article est dans la continuité de la série sur l’industrialisation de PostgreSQL. Nous allons voir dans celui-ci comment mettre en place la supervision de nos instances PostgreSQL à l’aide de pglift, en intégrant Prometheus, Grafana et Alertmanager pour un monitoring complet et efficace.
Pourquoi superviser PostgreSQL ?
La supervision des instances PostgreSQL est essentielle pour assurer leur performance, leur disponibilité et leur fiabilité dans un environnement de production. Elle permet de détecter les anomalies, les goulots d’étranglement et les défaillances avant qu’elles n’impactent les applications qui en dépendent.
Avec pglift, la supervision est intégrée directement dans le processus de déploiement des instances, facilitant ainsi l’adoption de bonnes pratiques dès la création de l’environnement.
![]()
Intégration de la supervision dans pglift
Lors du déploiement d’une instance avec pglift, il est possible de créer un rôle dédié
à la supervision, membre du rôle système pg_monitor, qui permet d’accéder aux vues
et fonctions de monitoring de PostgreSQL sans droits excessifs. De plus, pglift déploie
automatiquement une configuration pour postgres_exporter, un exporter Prometheus
qui collecte les métriques de l’instance et les expose sur un port dédié.
Voici un exemple de configuration pglift incluant la section prometheus :
postgresql:
replrole: 'replication'
auth:
host: scram-sha-256
backuprole:
name: backup
pgpass: true
pgbackrest:
configpath: '/etc/pgbackrest'
repository:
path: /var/lib/pgsql/backups
mode: path
systemd: {}
prometheus:
execpath: /usr/bin/postgres_exporter
configpath: /etc/prometheus/postgres_exporter-{name}.conf
Cette configuration indique le chemin vers l’exécutable de postgres_exporter
ainsi que le chemin pour les fichiers de configuration, qui seront générés automatiquement
par pglift pour chaque instance.
Déploiement avec Ansible
Pour déployer une instance avec supervision activée, voici un exemple de playbook
Ansible utilisant le module dalibo.pglift.instance :
- name: Create Instances
hosts: srv-pg1
become_user: postgres
become: true
tasks:
- name: Managing instances
dalibo.pglift.instance:
name: main
state: started
version: 17
port: 5432
surole_password: "Passw0rd"
replrole_password: "Passw0rd"
pgbackrest:
password: "Passw0rd"
stanza: main-stz
settings:
listen_addresses: '*'
prometheus:
password: "Passw0rd"
Dans ce playbook, la section prometheus permet de définir le mot de passe pour le
rôle de supervision. pglift créera alors automatiquement le rôle prometheus (membre
de pg_monitor) et configurera postgres_exporter pour qu’il se lance au démarrage
de l’instance, exposant les métriques sur le port 9187 par défaut.
Une fois l’instance déployée par pglift, il est possible de voir le statut de l’exporter ainsi :
$ pglift instance status
PostgreSQL: running
prometheus: running
La ligne prometheus: running indique que l’exporter est en cours d’exécution.
La commande suivante permet d’afficher les métriques PostgreSQL exposées par l’exporter postgres-exporter, afin de les consulter directement au sein du terminal :
$ curl http://localhost:9187/metrics
[...]
pg_locks_count{datname="postgres",mode="accessexclusivelock"} 0
pg_locks_count{datname="postgres",mode="accesssharelock"} 1
pg_locks_count{datname="postgres",mode="exclusivelock"} 0
pg_locks_count{datname="postgres",mode="rowexclusivelock"} 0
pg_locks_count{datname="postgres",mode="rowsharelock"} 0
pg_locks_count{datname="postgres",mode="sharelock"} 0
pg_locks_count{datname="postgres",mode="sharerowexclusivelock"} 0
pg_locks_count{datname="postgres",mode="shareupdateexclusivelock"} 0
pg_locks_count{datname="postgres",mode="sireadlock"} 0
# HELP pg_scrape_collector_duration_seconds postgres_exporter: Duration of a collector scrape.
# HELP pg_scrape_collector_success postgres_exporter: Whether a collector succeeded.
pg_settings_allow_alter_system{server="/run/user/1001/pglift/postgresql:5432"} 1
pg_settings_allow_in_place_tablespaces{server="/run/user/1001/pglift/postgresql:5432"} 0
pg_settings_allow_system_table_mods{server="/run/user/1001/pglift/postgresql:5432"} 0
pg_settings_archive_timeout_seconds{server="/run/user/1001/pglift/postgresql:5432"} 0
[...]
Configuration de Prometheus
Une fois l’instance déployée, il faut configurer Prometheus pour scraper les métriques
exposées par postgres_exporter. Voici une configuration minimale
(dans /etc/prometheus/prometheus.yml) :
global:
scrape_interval: 15s
evaluation_interval: 15s
rule_files:
- 'rules.d/*.yml'
scrape_configs:
- job_name: "postgresql"
static_configs:
- targets:
- "srv-pg1:9187"
- "srv-pg2:9187"
Cette configuration définit un intervalle de scraping de 15 secondes, inclut les fichiers de règles d’alerte, et liste les cibles (instances PostgreSQL) à surveiller. Prometheus collectera alors automatiquement les métriques telles que l’utilisation du CPU, de la mémoire, le nombre de connexions, etc.
La section scrape_configs définit les jobs de scraping. Ici, le job nommé “postgresql”
configure Prometheus pour scraper les métriques exposées par postgres_exporter sur
le port 9187 des hôtes srv-pg1 et srv-pg2.
Règles d’alerte Prometheus
Pour compléter la configuration de Prometheus, il est essentiel de définir des règles d’alerte basées sur les métriques collectées. Un ensemble de règles prédéfinies pour PostgreSQL est disponible sur GitHub : postgres_exporter Rules
Pour notre cas, cet exemple peut être placé dans le fichier /etc/prometheus/rules.d/postgresql-rules.yml.
Ces règles couvrent des alertes courantes telles que la disponibilité de l’instance,
l’utilisation des ressources, les erreurs de connexion, etc. Elles permettront à
Prometheus de générer des alertes qui seront ensuite gérées par Alertmanager.
Visualisation avec Grafana
Pour visualiser les métriques collectées par Prometheus, Grafana est l’outil de référence. Il permet de créer des tableaux de bord interactifs et personnalisables.
Un tableau de bord PostgreSQL est disponible sur le site de Grafana : Dashboard Grafana
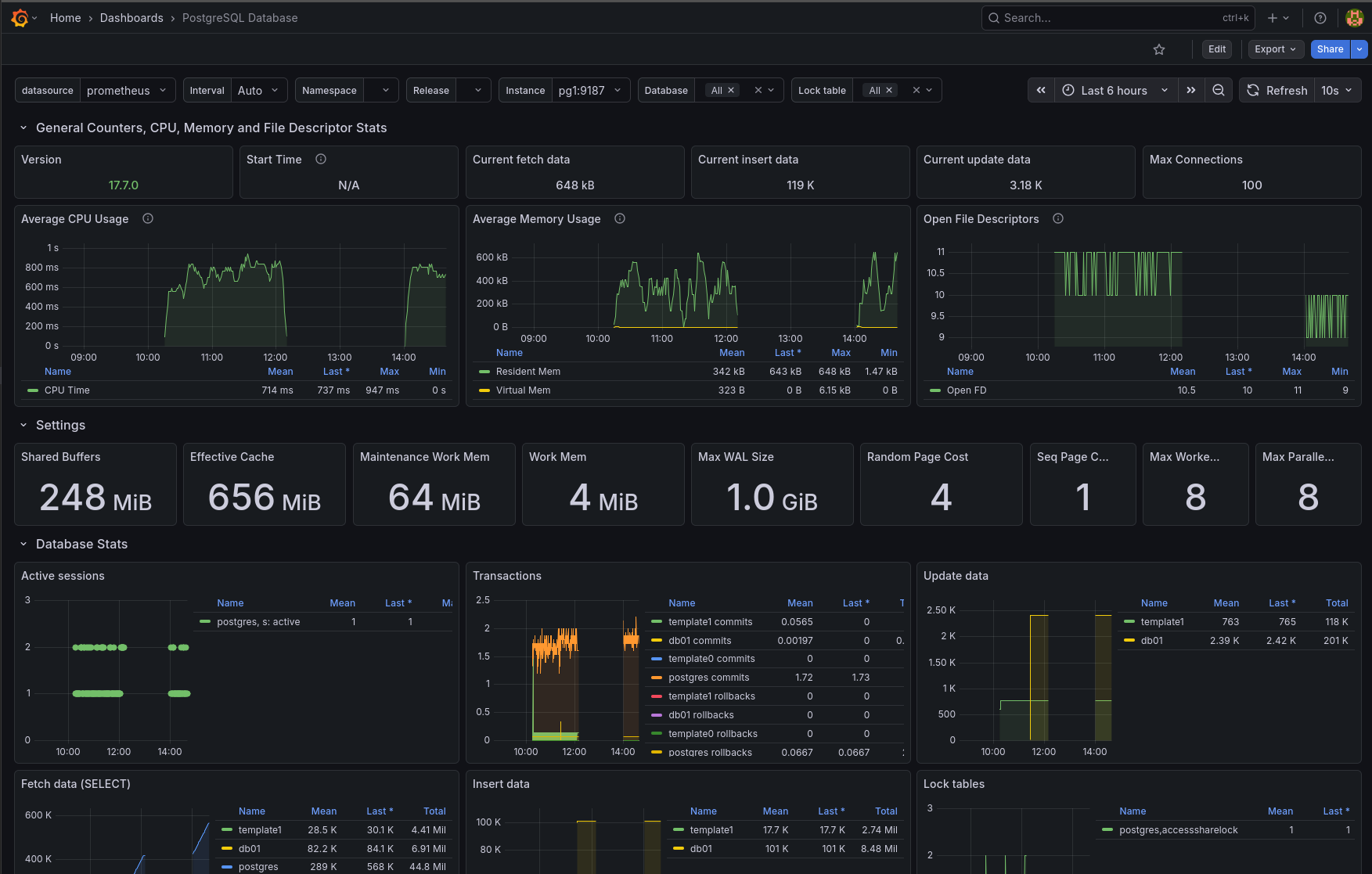
Ce dashboard fournit une vue d’ensemble des performances de l’instance, incluant des graphiques sur les requêtes actives, l’utilisation des ressources, les locks, etc. Il suffit de l’importer dans Grafana en connectant une source de données Prometheus.
Alertes avec Alertmanager
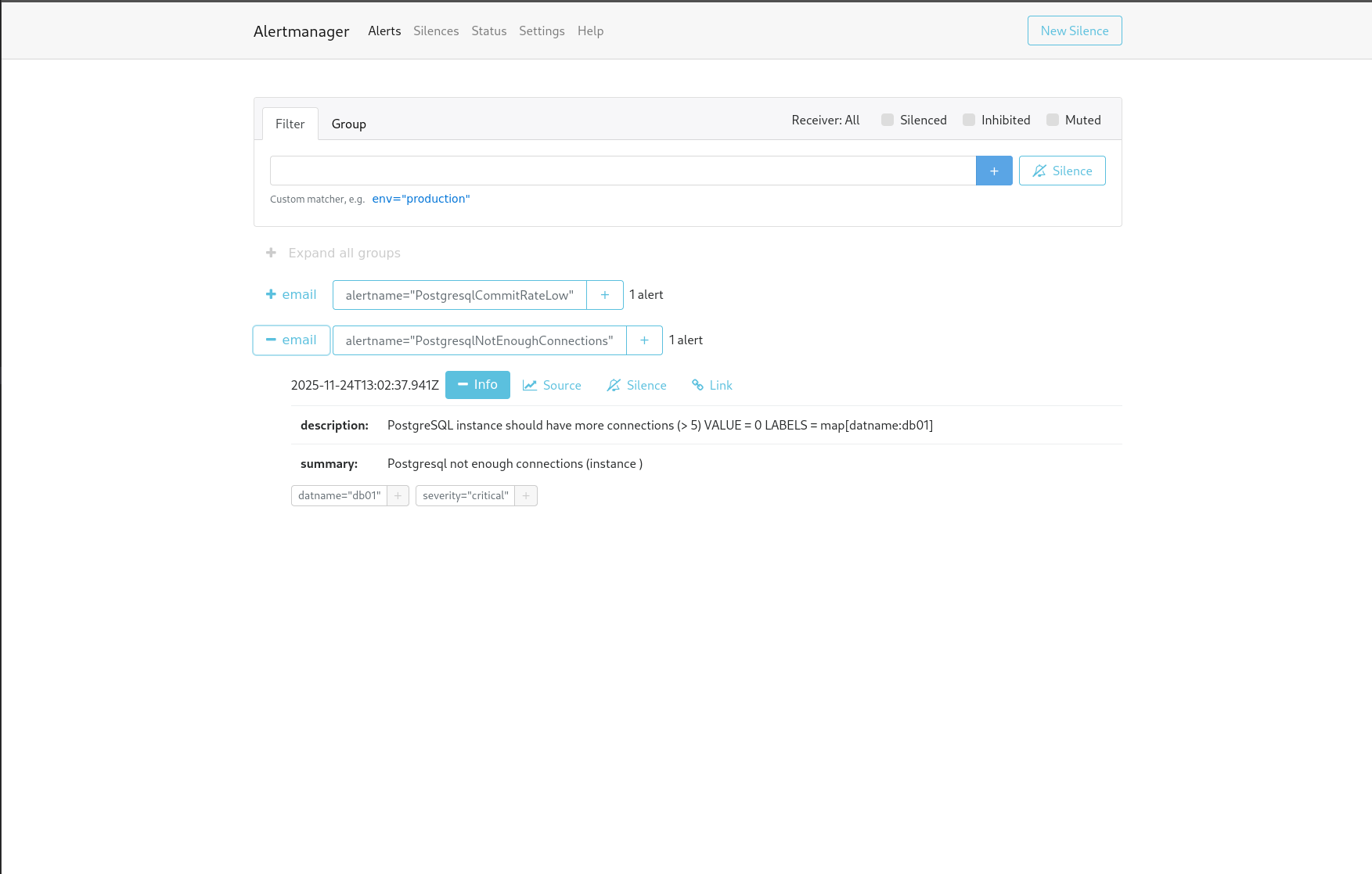
Enfin, pour compléter la supervision, Alertmanager permet de gérer les alertes générées par Prometheus. Il peut envoyer des notifications par email, Slack, PagerDuty, etc., en cas de seuils dépassés.
Voici un exemple de configuration Alertmanager pour les alertes PostgreSQL :
global:
smtp_smarthost: 'smtp.example.com:587'
smtp_from: 'alertmanager@example.com'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: 'monitoring@example.com'
Cette configuration envoie des emails à l’adresse “monitoring@example.com” en cas d’alertes.
Pour un premier démarrage d’Alertmanager, lancez-le avec la commande suivante :
alertmanager --config.file=alertmanager.yml
Où alertmanager.yml est le fichier de configuration présenté ci-dessus. Alertmanager
sera alors accessible sur le port 9093 par défaut.
Enfin, configurez Prometheus pour qu’il envoie les alertes à Alertmanager en ajoutant dans sa configuration globale :
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
Ressources
Conclusion
La supervision est un pilier de l’exploitation des bases de données PostgreSQL en production. Grâce à pglift, l’intégration de Prometheus, Grafana et Alertmanager est simplifiée, permettant un déploiement rapide et homogène des outils de monitoring.
- PostgreSQL (471) ,
- Dalibo (196) ,
- ansible (5) ,
- pglift (12) ,
- supervision (17) ,
- prometheus (1) ,
- grafana (1) ,
- planetpgfr (48)