Vallée de Munster, 04 novembre 2025
La haute disponibilité dans nos métiers de l’IT est un vaste sujet. PostgreSQL étant au cœur de nombreux Systèmes d’Information, il est souvent source de nombreuses questions pour construire des architectures robustes, redondantes et hautement disponibles.
Cet article propose une brève présentation de Patroni : son rôle, les composants essentiels pour l’utiliser, ainsi que quelques bonnes pratiques. Nous aborderons également l’usage de notre socle technique d’industrialisation pour exploiter Patroni.
Patroni, de quoi parlons-nous ?
Patroni est une solution de « template » pour gérer une ou des grappes (Clusters) d’instances PostgreSQL. En fonction de la configuration retenue, Patroni permet d’assurer la haute disponibilité d’un service PostgreSQL, de maintenir l’agrégat en condition opérationnelle, de le superviser et provoquer une bascule automatique en cas d’incident.
Composants
Nous retrouvons dans le schéma suivant l’ensemble des composants minimum requis pour mettre en place une grappe de serveurs PostgreSQL avec Patroni.
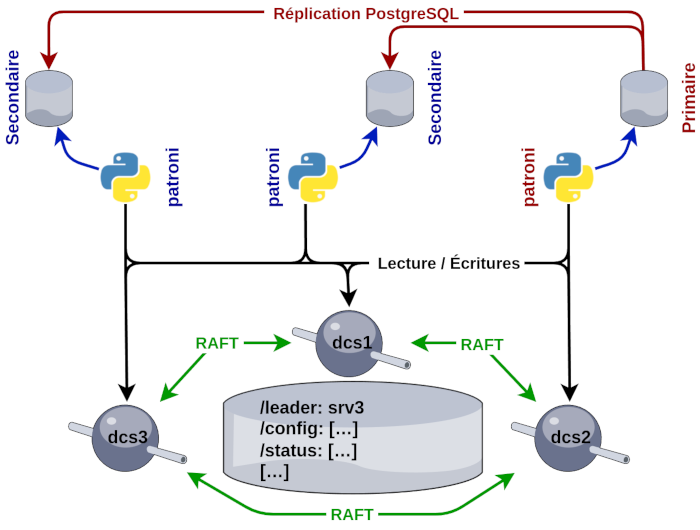
- Patroni est un service écrit en Python qui va piloter le cycle de vie des instances PostgreSQL en se basant sur un système distribué (cf. DCS ci-dessous)
- un DCS (Distributed Consensus Store ou parfois appelé Distributed Configuration Store), ce composant permet de partager l’état des nœuds, leur configuration au sein du cluster et de garantir l’unicité du rôle leader. C’est la source de vérité principale d’un cluster Patroni. La littérature et nos observations montrent qu’etcd est souvent adopté pour assurer ce rôle.
- PostgreSQL ! Dans l’architecture que nous présentons, PostgreSQL (notre SGBD de cœur ❤️ ) est piloté par Patroni. Ce dernier utilise des fonctionnalités natives de PostgreSQL (Exemple : la réplication physique de PostgreSQL).
En complément de ces composants, on peut retrouver, entre autres, les éléments optionnels suivants :
- Une solution de sauvegarde au fil de l’eau de type PITR (par exemple pgBackrest, Barman,…)
- Un aiguilleur de connexions (par exemple HAProxy)
Configuration de notre SGBD favori - statique vs dynamique
Dans l’architecture que nous présentons, Patroni se charge de gérer le cycle de vie des instances PostgreSQL. Il va initier et configurer les instances PostgreSQL sur la base de sa configuration et de l’état du cluster. Les utilisateur·ices ont plusieurs choix possibles pour configurer PostgreSQL :
-
En utilisant une configuration dite statique de Patroni (qui s’applique à un seul nœud) :
- Via le fichier de configuration (YAML) de Patroni, en éditant la section postgresql dudit fichier
- En définissant des variables d’environnement au démarrage de Patroni
(entre autres les variables
PATRONI_POSTGRESQL_*pour altérer la configuration de PostgreSQL)
-
En utilisant la configuration dite dynamique de Patroni. Cette configuration s’applique à l’ensemble des instances de notre Cluster et est stockée dans le
DCS. Elle est modifiable via la commandepatronictl edit-configet consultable avecpatronictl show-config.La configuration suivante, s’applique à l’ensemble des instances PostgreSQL de notre grappe :
$ patronictl show-config loop_wait: 10 postgresql: parameters: max_connections: 50et est appliquée par Patroni à l’ensemble des instances PostgreSQL :
$ psql psql (17.2 (Debian 17.2-1.pgdg120+1)) Type "help" for help. [17/pg1] postgres@~=# show max_connections; max_connections ----------------- 50 (1 row)
Pièges classiques
Attention, Certaines options sont exclusivement paramétrables
dynamiquement (au niveau
DCS),
c’est le cas, entre autre, de l’option max_connections. Pour les
autres paramètres, lorsqu’on utilise les deux méthodes de configuration
(fichier et DCS), la majorité des options statiques prévalent.
Par exemple, si l’utilisateur⋅ice attribue 8 Go pour le paramètre
shared_buffers
dans le fichier de configuration de Patroni et utilise une autre valeur
dans la configuration dynamique (DCS), seule la configuration
statique (définie dans le fichier) sera prise en compte et appliquée
au nœud (et non à l’ensemble du Cluster).
Par exemple, nous montrons ici la modification d’un paramètre dynamique et sa non prise en compte par Patroni / PostgreSQL :
-
On positionne la valeur de l’option
shared_buffersà8 GBdans le fichier de configuration de Patroni :$ cat ${PATRONICTL_CONFIG_FILE} | yq -r .postgresql.parameters.shared_buffers 8 GB -
On modifie ensuite la valeur du
shared_buffersdans la configuration dynamique :$ patronictl edit-config --force -p shared_buffers='4 GB' -
On relance notre ou nos instances PostgreSQL :
$ patronictl restart pgdemo When should the restart take place (e.g. 2025-01-23T10:18) [now]: Are you sure you want to restart members pg1? [y/N]: y Restart if the PostgreSQL version is less than provided (e.g. 9.5.2) []: 18.0 Success: restart on member pg1 -
Pour, au final, observer la non prise en compte de la configuration dynamique :
$ psql psql (17.2 (Debian 17.2-1.pgdg120+1)) Type "help" for help. [17/pg1] postgres@~=# show shared_buffers; shared_buffers ---------------- 8GB (1 row)
Ce comportement bien que décrit dans la documentation, peut être source de confusion. Il peut conduire à une forme de disparité non souhaitable au sein d’un Cluster d’instances PostgreSQL.
Et notre Socle dans l’équation ?!
Notre solution d’industrialisation, le Socle Postgres Dalibo, et son composant central pglift, depuis la version 2.5, offrent la possibilité de choisir entre une configuration statique ou dynamique.
Par défaut, pglift utilise une configuration locale, mais les utilisateur·ices peuvent modifier ce comportement en utilisant la configuration suivante :
patroni:
[...]
configuration_mode:
auth: dynamic
parameters: dynamic
Ces options permettent de choisir de gérer dynamiquement les entrées HBA et la configuration de PostgreSQL. Concrètement :
- lors de la création d’un Cluster, celui-ci sera initialisé avec les entrées HBA et la configuration PostgreSQL stockées dans le DCS ;
- toute modification d’un paramètre (HBA ou configuration) mettra automatiquement à jour les informations correspondantes dans le DCS (via l’API de Patroni).
À titre d’exemple, nous créons ici une instance gérée par Patroni via pglift :
$ pglift instance create main1 --port=5974 --patroni-cluster=pgdemo --patroni-node=main1
INFO initializing PostgreSQL
INFO setting up Patroni service
INFO bootstrapping PostgreSQL with Patroni
...
INFO configuring PostgreSQL
INFO altering role 'replrole'
INFO creating instance dumps directory: /srv/data/17-main1
Lors de l’initialisation, Patroni est configuré (par pglift) de manière à garnir le DCS en utilisant les modèles de configuration fournis par pglift :
$ pglift instance exec main1 -- patronictl show-config
loop_wait: 10
postgresql:
parameters:
effective_cache_size: 22 GB
shared_buffers: 8 GB
...
pg_hba:
- local all postgres trust
- local all backup trust
...
Les utilisateur·rices peuvent ensuite modifier la configuration
dynamique soit via la commande pglift (Exemple :
pglift pgconf -i main1 set max_connections='30'), soit via Ansible :
---
- name: Manage primary instance
hosts: localhost
tasks:
- name: Create primary instance pg1
dalibo.pglift.instance:
name: main1
port: 5974
state: started
settings:
max_connections: 40
patroni:
cluster: pgdemo
node: main1
$ ansible-playbook /tmp/patroni.yml
...
TASK [Manage primary instance pg1] *************
changed: [localhost]
...
Peu importe l’interface utilisée, pglift va appeler l’API de Patroni pour modifier la configuration distribuée :
$ pglift instance exec main1 -- patronictl show-config |\
yq -r .postgresql.parameters.max_connections
30
pglift, que ce soit via sa ligne de commande ou via Ansible, permet de faire abstraction du type d’instance. Ainsi, une instance gérée par Patroni, malgré certaines spécificités, peut être configurée de manière similaire à une instance plus simple (par exemple, une instance standalone).
Quelques pratiques et recommandations
Patroni offre plusieurs choix pour stocker sa configuration, mais aussi les paramètres spécifiques pour PostgreSQL. Les deux techniques ont du sens et le choix entre configuration dynamique ou statique va dépendre de plusieurs critères.
Voici quelques questions pertinentes pour choisir l’une ou l’autre option :
- Ma configuration est-elle globale à l’ensemble des instances PostgreSQL d’une grappe ?
- Dois-je appliquer un ensemble de paramètres à un seul nœud (ou un groupe limité de nœuds) ?
- Est-il possible et facile de déployer la configuration avec des outils d’automatisation (Exemple via un Playbook Ansible) ?
Lors de l’utilisation de Patroni, nous recommandons de définir et suivre une stratégie adaptée et documentée pour configurer Patroni et PostgreSQL. Il nous semble intéressant et utile de :
-
S’appuyer sur des outils de déploiement et d’automatisation pour mettre en place et maintenir votre configuration (Ansible, Puppet, cfengine,…).
Cette approche permet de maintenir en un seul endroit (Exemple : un entrepôt Git) l’ensemble de votre configuration. Cela facilite grandement la gestion de vos instances (modification, audit,…).
-
limiter au strict minimum l’utilisation simultanée d’une configuration statique (fichier de configuration) et dynamique (DCS).
Notamment, lorsqu’on utilise un DCS comme source de configuration, il nous semble idéal d’y consigner les paramètres communs à toutes les instances.
Conclusions & ressources
Patroni est une solution de haute disponibilité largement reconnue et utilisée depuis plusieurs années, qui a progressivement intégré de nombreuses fonctionnalités pour répondre aux besoins des utilisateurs.
En raison de la complexité et des enjeux de la haute disponibilité, Dalibo a investi significativement dans la R&D autour de Patroni, grâce aux contributions de ses DBA et développeur·euse·s ainsi qu’aux retours récurrents de ses clients.
Les divers chantiers concernant Patroni, nous ont permis entre autres de produire :
-
L’implémentation du support de Patroni dans notre solution d’industrialisation